kafka 설정을 사용한 문제해결
메일 시스템 구조개선을 진행하면서 kafka를 사용하며 부딪혔던 문제와 해결했던 방법을 공유하여
같은 문제를 겪을 수 있는 분들에게 도움이 되고자 작성하게 되었습니다.
최근 시스템솔루션개발파트에서는 MSA구조로 개선하는 프로젝트를 진행하고 있습니다. 이에 일환으로 메일 시스템의 구조개선을 진행하였습니다. 구조개선에 대한 자세한 설명은 이전 포스트를 참고 부탁드립니다.
kafka란?
먼저 카프카(kafka)에 대해 간단하게 설명드리면, 아파치 카프카(Apache Kafka)는 LinkedIn에서 개발된 분산 메시징 시스템입니다. 발행-구독(publish-subscribe) 모델을 기반으로 동작하며 크게 producer, consumer, connectors, streams processors, broker로 구성됩니다.
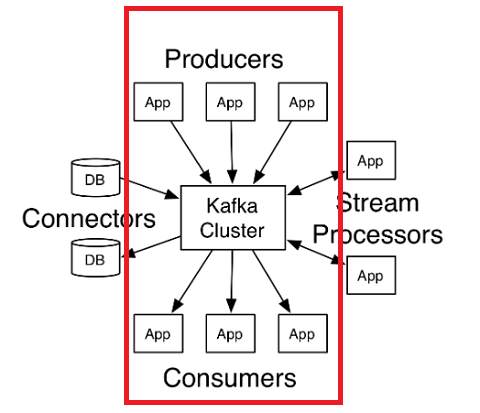
카프카의 브로커(broker)는 토픽(topic)을 기준으로 메시지를 관리합니다.
프로듀서(producer)는 특정 토픽의 메시지를 생성한 뒤 해당 메시지를 브로커에게 전달합니다. 브로커가 전달받은 메시지를 토픽별로 분류하여 쌓아놓으면,
해당 토픽을 구독하는 컨슈머(consumer)들이 메시지를 가져가서 처리하게 됩니다.
카프카는 확장성(scale-out)과 고가용성(high availability)을 위하여 브로커들이 클러스터로 구성되어 동작하도록 설계되어있습니다.
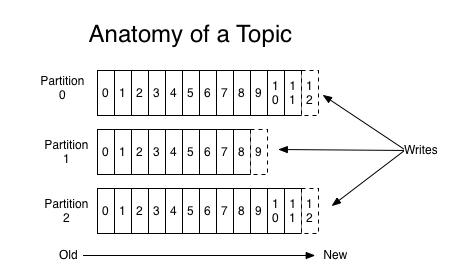
1) 토픽(topic), 파티션(partition)
카프카 클러스터는 토픽이라는 곳에 데이터를 저장합니다.
카프카에 저장되는 메시지는 토픽으로 분류되고 토픽은 여러개의 파티션으로 나눠집니다.
파티션안에는 메시지의 위치를 나타내는 오프셋(offset)이 있는데, 이 오프셋 정보를 이용해서 가져간 메시지의 위치정보를 알 수 있습니다.
2) 컨슈머(consumer), 컨슈머그룹(consumer group)
컨슈머는 카프카 토픽에서 메시지를 읽어오는 역할을 합니다.
컨슈머 그룹은 하나의 토픽에 여러 컨슈머 그룹이 동시에 접속해 메시지를 가져올 수 있습니다.
컨슈머그룹은 컨슈머가 프로듀서의 메시지 생성 속도를 따라가지 못할 때, 컨슈머 확장을 용이하게 할 수 있도록 하기위한 기능입니다.
예를들어, 프로듀서가 토픽에 보내는 메시지 속도가 갑자기 증가해 컨슈머가 메시지를 가져가는 속도보다 빨라지면 어떻게 될까요?
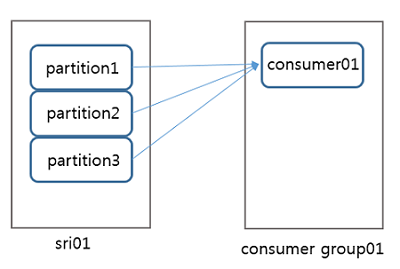
컨슈머그룹 아이디 : consumer group01
컨슈머 : consumer01
토픽: sri01
토픽의 파티션 수: 3
consumer01이 메시지를 가져가는 속도보다 프로듀서가 메시지를 보내는 속도가 더 빨라지게되고, sri01 토픽에는 시간이 지남에 따라 consumer01이 아직 읽어가지 못한 메시지들이 점점 쌓이게 될 것입니다.
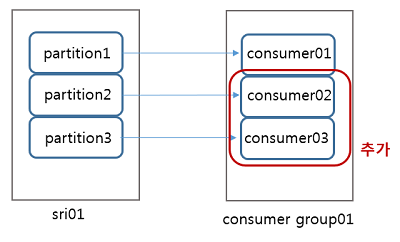
이러한 경우, 컨슈머 그룹 consumer group01 에 컨슈머 consumer02, consumer03 을 추가해서 아래의 그림과 같이 내부적으로 균형을 맞추도록 할 수 있습니다.
동일한 컨슈머그룹내에서 컨슈머가 추가되면 consumer01이 가지고 있는 소유권이 consumer02, consumer03으로 이동하게 되어 균형을 맞출 수 있습니다.
3) 리밸런스(rebalance)
컨슈머 그룹안에서 컨슈머들은 메시지를 가져오고 있는 토픽의 파티션에 대해 소유권을 공유하고 있습니다. 컨슈머가 추가되거나 삭제되었을 때 토픽에 대한 소유권이 이동하게 되는데,
이를 리밸런스(rebalance) 라고 합니다.
리밸런스를 하는 동안에는 일시적으로 컨슈머는 메시지를 가져올 수 없습니다.
리밸런스가 일어나면 토픽의 각 파티션마다 하나의 컨슈머가 연결되고, 리밸런스가 끝나면 컨슈머들은 각자 담당하고 있는 파티션으로부터 메시지를 가져오게 됩니다.
리밸런스가 일어난 후 각각의 컨슈머는 이전에 처리했던 토픽의 파티션이 아닌 다른 새로운 파티션에 할당됩니다.
컨슈머는 새로운 파티션에 대해 가장 최근 커밋된 오프셋을 읽고, 그 이후부터 메시지들을 가져오기 시작합니다.
문제 해결 과정 및 방법
이번 메일 시스템 구조개선 프로젝트를 진행하면서 겪었던 문제는 크게 두 가지 입니다.
1) 메시지가 중복소비 되면서 발생한 문제
2) 낮은 처리량으로 인한 문제
1) 메시지가 중복소비 되면서 발생한 문제
메시지가 중복소비되는 문제의 해결과정을 먼저 간략하게 정리하면 다음과 같습니다.
- 메시지가 중복 소비되는 현상을 발견
- 해당 토픽의 상세 정보 확인
- 토픽의 오프셋 커밋 체크 -> 오프셋 커밋이 잘 되고있는지 확인
- 리밸런스가 일어나는 현상 확인
메시지가 중복 소비되는 현상을 발견
컨슈머에서 메시지를 정상적으로 처리하고 있는지를 확인하는 도중에 메시지가 중복으로 소비되고 있는 현상을 발견하게 되었습니다.
해당 토픽 상세 정보 확인
카프카에서 기본적으로 제공해주는 명령어들이 있으며, 해당 명령어의 리스트는 설치경로의 bin 디렉토리에 있습니다. 명령어 중 컨슈머 그룹상태와 오프셋을 확인하기 위한 명령어를 사용하여 문제 토픽의 상세정보를 확인하였습니다.
카프카에서는 컨슈머 그룹상태와 오프셋을 확인하기 위해 kafka-consumer-groups.sh 명령어를 제공합니다.

–bootstrap-server : 브로커 리스트를 입력합니다.
–group : 컨슈머 그룹 입력, 토픽명을 입력하면 해당 토픽에 관한 상세 정보만 볼 수 있습니다.
–describe : describe 옵션을 추가하여 클러스터에 있는 하나 이상의 토픽에 관한 상세정보를 볼 수 있습니다.
위 명령어를 통해 아래의 결과 화면과 같이 그룹의 멤버정보, 현재 오프셋, 마지막 오프셋, LAG 정보 등을 확인할 수 있습니다. LAG는 현재 토픽의 저장된 메시지와 컨슈머가 가져간 메시지의 차이를 뜻하는데, LAG 숫자가 높다는 것은 해당 토픽 또는 컨슈머가 읽어가지 못한 메시지가 많다는 것입니다.

| 필드 | 설명 |
| TOPIC | 소비되는 토픽의 이름 |
| PARTITION | 소비되는 파티션의 ID번호 |
| CURRENT-OFFSET | 컨슈머 그룹에 의해 커밋된 이 토픽 파티션의 마지막 오프셋. 해당 필드가 파티션 내부의 컨슈머의 위치 |
| LOG-END-OFFSET | 해당 토픽 파티션에 저장된 데이터의 끝을 나타내며(브로커가 관리함), 파티션에 쓰고 클러스터에 커밋된 마지막 메시지의 오프셋이다. |
| LAG | 컨슈머 Current-Offset과 브로커의 Log-End-Offset 간의 차이(메시지 수)를 나타낸다. |
토픽의 오프셋 커밋 체크 및 리밸런스 현상 확인
토픽의 상세정보에서 오프셋 정보를 확인해보니 오프셋 커밋이 정상적으로 이뤄지지 않고 있다는걸 알게되었습니다. LAG이 계속 증가하는 상황이 지속되다가, 늦은 속도로 1~2개 정도 감소한 후 멈춰지고 리밸런싱이 일어났습니다.
여러개의 토픽 중 문제가 되는 토픽의 LAG 만 이러한 문제가 발생하였고, 다른 토픽들은 빠른속도로 처리가 되고있었습니다. 특정 토픽의 오프셋 커밋이 정상적으로 이루어 지지 않는다는것을 확인하고, 에러로그를 먼저 확인해보았지만 별다른 문제는 없었습니다.
그래서 컨슈머와 브로커 사이의 흐름에 어떠한 문제로 오프셋 커밋이 정상적으로 이루어지지 않아 리밸런스가 발생했는지에 대해 알아보게 되었습니다.
왜 오프셋 커밋(offset commit)이 정상적으로 이루어지지 않고, 리밸런스(rebalance)가 일어나면서 메시지가 중복으로 소비되었는지를 찾기위해 컨슈머 주요 옵션에서 리밸런스를 발생시킬 수 있는 상황을 살펴보았습니다.
1) session.timeout.ms 설정시간에 heartbeat 시그널을 받지 못해 리밸런스가 발생하는 경우 2) max.poll.interval.ms 설정시간에 poll() 메소드가 호출되지 않아 리밸런스가 발생하는 경우
| 옵션명 | 설명 | 기본값 |
|---|---|---|
session.timeout.ms | 컨슈머와 브로커사이의 session timeout 시간. 컨슈머가 살아있는것으로 판단하는 시간으로 이 시간이 지나면 해당 컨슈머는 종료되거나 장애가 발생한것으로 판단하고 컨슈머 그룹은 리밸런스를 시도한다. 이 옵션은 heartbeat 없이 얼마나 오랫동안 컨슈머가 있을 수 있는지를 제어하며 heartbeat.interval.ms와 밀접한 관련이 있어서 일반적으로 두 속성이 함께 수정된다. | 10000 (10초) |
heartbeat.interval.ms | 컨슈머가 얼마나 자주 heartbeat을 보낼지 조정한다. session.timeout.ms보다 작아야 하며 일반적으로 1/3로 설정 | 3000 (3초) |
max.poll.interval.ms | 컨슈머가 polling하고 commit 할때까지의 대기시간. 컨슈머가 살아있는지를 체크하기 위해 hearbeat를 주기적으로 보내는데, 계속해서 heartbeat만 보내고 실제로 메시지를 가져가지 않는 경우가 있을 수 있다. 이러한 경우에 컨슈머가 무한정 해당 파티션을 점유할 수 없도록 주기적으로 poll을 호출하지 않으면 장애라고 판단하고 컨슈머 그룹에서 제외시키도록 하는 옵션이다. | 300000 (5분) |
max.poll.records | 컨슈머가 최대로 가져 갈 수있는 갯수. 이 옵션으로 polling loop에서 데이터 양을 조정 할 수 있다. | 500 |
enable.auto.commit | 백그라운드로 주기적으로 offset을 commit | true |
auto.commit.interval.ms | 주기적으로 offset을 커밋하는 시간 | 5000 (5초) |
auto.offset.reset | earliest: 가장 초기의 offset값으로 설정 latest: 가장 마지막의 offset값으로 설정 none: 이전 offset값을 찾지 못하면 error 발생 | latest |
첫번째로. session timeout 시간이 지난 경우
컨슈머 옵션들을 살펴보며 처음엔 session.timeout.ms 와 heartbeat.interval.ms 설정을 수정해보았습니다.
session.timeout.ms 시간을 점점 늘려보며 응답이 올때까지 기다리도록 했습니다.
하지만 세션타임아웃 설정값을 늘릴 수록 리밸런스가 일어났을 때 걸리는 시간만 늦어질 뿐
문제가 해결되지 않았습니다.
문제는 컨슈머가 메시지를 가져와서 처리하고 커밋하기까지의 시간을 조절할 수 있는 옵션을 수정해야하는데, 이 설정은 서버(kafka broker)와 클라이언트(consumer) 와의 세션 타임아웃 시간을 조절할 수 있는 옵션이라 직면했던 문제상황에는 맞지 않았습니다.
두번째로. poll을 호출하는 시간 간격 확인
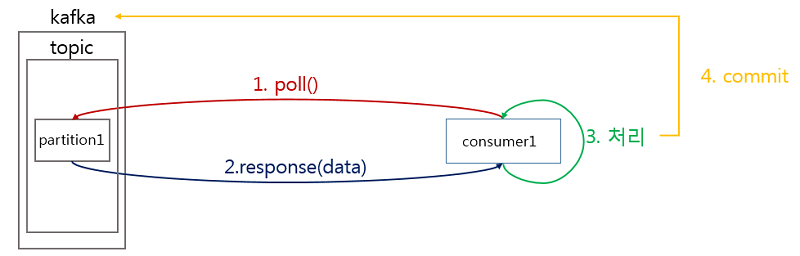
컨슈머는 메시지를 가져오기위해 브로커에 poll()요청을 보내고, 컨슈머는 가져온 메시지를 처리한 후, 해당 파티션의 offset을 커밋하게 됩니다. poll요청을 보내고 다음 poll을 요청을 보내는데 까지의 시간이 max.poll.interval.ms의 기본값인 300000 (5분) 보다 늦으면 브로커는 컨슈머에 문제가 있다고 판단하여 리밸런싱을 일으키게 됩니다.
max.poll.interval.ms 기본값 : 300000(5분)
max.poll.records 기본값 : 500
위와 같이 기본값으로 설정이 되면,
한번의 poll메소드를 통해 최대 500개까지의 레코드를 가져오게 됩니다. 디버깅을 해보니, 처리하는 로직에 포함되어 있는 DB 쿼리문이 조회되는 시간만 1분30초~2분 정도의 시간이 걸렸습니다. (몇번의 호출 후에는 조회 속도가 빨라져서 소요시간이 일정하지 않음)
즉, 하나의 레코드를 처리하는데 1분이라고 한다면, 최대 500개의 레코드를 처리하는데 걸리는 시간은 약 500분이 걸립니다.
이는 max.poll.interval.ms 기본값인 5분보다 늦으므로 브로커는 컨슈머에 문제가 있다고 판단하여 컨슈머가 컨슈머 그룹에서 제외된 것입니다.
컨슈머 그룹에서 컨슈머가 제외되면서 리밸런스가 일어나게 되었고,
새로 할당된 파티션의 커밋된 오프셋이 컨슈머가 실제 마지막으로 처리한 오프셋보다 작아서 메시지가 중복처리된 것입니다.
그래서 poll요청을 보내고 다음 poll을 요청을 보내는데 까지의 시간을 설정할 수 있는 max.poll.interval.ms 설정값과 최대로 가져올 수 있는 레코드 수를 설정할 수 있는 max.poll.records 설정값을 수정해보았습니다.
max.poll.interval.ms : 600000(10분)
max.poll.records : 2
위와 같이 설정하면, 한번의 poll 메소드를 통해 두 개의 레코드를 가져오게 됩니다.
즉, 하나의 레코드를 처리하는데 2분이라고 한다면, 두 개의 레코드를 처리하는데 걸리는 시간은 약 4분이 걸리게 됩니다. 이는 max.poll.interval.ms 설정값보다 적게 걸리므로 메시지 소비 도중 리밸런스가 일어나지 않았고, 메시지가 중복소비되는 이슈를 해결할 수 있었습니다.
2) 낮은 처리량으로 인한 문제
컨슈머 옵션을 수정하여 리밸런스가 일어나면서 생기는 문제는 해결하였지만,
메시지가 소비되는 속도가 생각보다 좋지않아서 처리량을 높여야 했습니다.
처리량을 높이기 위해서는 토픽의 파티션 수를 늘리고 컨슈머의 수도 같이 늘려주어 해결할 수 있습니다.
먼저, 파티션의 수는 토픽을 생성할 때 정해집니다. 카프카에서 제공해주는 명령어를 이용하여 토픽을 생성 할 수 있고, 추가적인 옵션을 통해 파티션 수를 입력할 수 있습니다.
토픽을 생성하기 위해 카프카에서 제공해주는 명령어는 kafka-topics.sh 입니다.

옵션
–bootstrap-server : 브로커 리스트
–replication-factor : 리플리케이션 팩터 수
–partitions : 파티션 수
–topic : 토픽 이름을 입력
–create
두번째로는 컨슈머의 수를 함께 늘려주어야 합니다. 각각의 서버에서 여러개의 컨슈머가 동작하도록 하기위해 노드의 concurrency를 늘려서 토픽의 파티션을 모두 활용 할 수 있도록 했습니다.
spring cloud stream kafka에서 제공해주는 concurrency 속성을 사용했으며, 사용 시 유의사항은 아래와 같습니다.
- 접두어로 반드시 spring.cloud.stream.bindings.
.consumer. 를 붙여야합니다. - 인바인딩(input bindings) 에서만 사용할 수 있습니다.
사용예시) spring.cloud.stream.bindings.input.consumer.concurrency=3.
마치며
카프카를 사용하고 앞으로 운영하기 위해서는 기능만을 가져다 쓰기보단 흐름과 이를 제어할 수 있는 설정들에 대한 이해가 필요한 것 같습니다. 전반적인 흐름과 제공해주는 설정에 대한 이해가 바탕이 되어있어야 문제가 발생했을때 원인을 빠르게 찾을 수 있고, 이에대한 해결책을 생각 할 수 있는것 같습니다. 또한 많은 데이터를 카프카에서 다룰 때에는 처리속도, 처리량 등을 고려해서 설정을 적용해야 한다는걸 알게되었습니다. 프로젝트를 진행하면서 문제를 찾고 이를 해결하기까지 많은 시간이 소요되었지만, 앞으로 메일 시스템 운영을 하면서 많은 도움이 될 것이라고 생각합니다.
감사합니다.