Heimdall - 로그 수집 관제 시스템

Heimdall - 로그 수집 관제 시스템
이번 블로그에서는 로그수집과 관제알림을 위해서 구축된 관제시스템
"Heimdall"에 대해서 공유하고자 합니다.
1. Heimdall 개요
1.1. Heimdall이란?
사람인HR에서 사용하던 기존 관제시스템에서 UI 및 기능을 개선한 관제시스템입니다.
Heimdall 유래
북유럽 신화의 아스가르드의 수문장으로 아홉 우주의 만물을 보고 들을 수 있다고 합니다.
그래서 모든 어플리케이션을 수집하고 분석하는 시스템이란 의미에서 Heimdall로 사용하였습니다.
1.2. Heimdall 주요 기능
- 어플리케이션 등의 로그를 수집하고 수집된 로그를 기반으로 검색이 가능합니다.
- 수집된 로그데이터를 각각의 그래프, DataTable,Map 등으로 표현될 수 있고..이것을 하나의 Dashboard로 구성이 가능합니다.
- 로그 내용을 기반으로 관제 조건을 설정할 수 있고, 관제 조건 부합 시 Telegram으로 관제 메시지를 전송이 가능합니다.
1.3. Heimdall 고도화 개선 내용
Heimdall 고도화는 기존 서버 기반에서 쿠버네티스 기반의 컨테이너로 서비스 배포 및 기동으로 전환되면서 기존 로그 수집과 컨테이이너 기반 로그 수집을 모두 수용할 수 있도록 개발이 진행되었습니다.
개발을 진행하면서 관리자 화면 및 기존에 불편한 부분에 대한 개선 및 신규 기능을 추가함으로써 사용자가 쉽게 로그를 수집하고 분석할 수 있도록 처리했습니다.
그리고 Kibana Dashboard에 로그 수집과 Metric에 대한 화면도 추가로 구성하였습니다.
주요 개선 내용은 다음과 같습니다.
- Heimdall 관리자 화면 UI 개선
- Jenkins 기반 배포에서 Gitlab/Docker/Kubernetes/Rancher 기반의 배포로 변경
-
모니터링/관제 개선
3.1. Container 기반 로그 수집
- Log 취합
- 로그 수집 분리
기존) Logstash -> ElasticSearch -> Kibana
신규) Filebeat -> Kafka -> Logstash -> ElasticSearch -> Kibana3.2. Container 기반 Metric 수집
- Metric 정보 취합
- Metric Dashboard 구성
- Metric Alert 구성 - ElastAlert을 사용한 관제 설정 추가
- 모니터링 분석을 위한 다양한 종류의 Kibana Dashboard 구성
2. Heimdall 시스템 구성
2.1. Heimdall 아키텍쳐
Heimdall은 컨테이너 기반 어플리케이션과 Baremetal 기반 어플리케이션에 대한 로그수집을 지원합니다.
| 컨테이너 기반 로그 수집 |
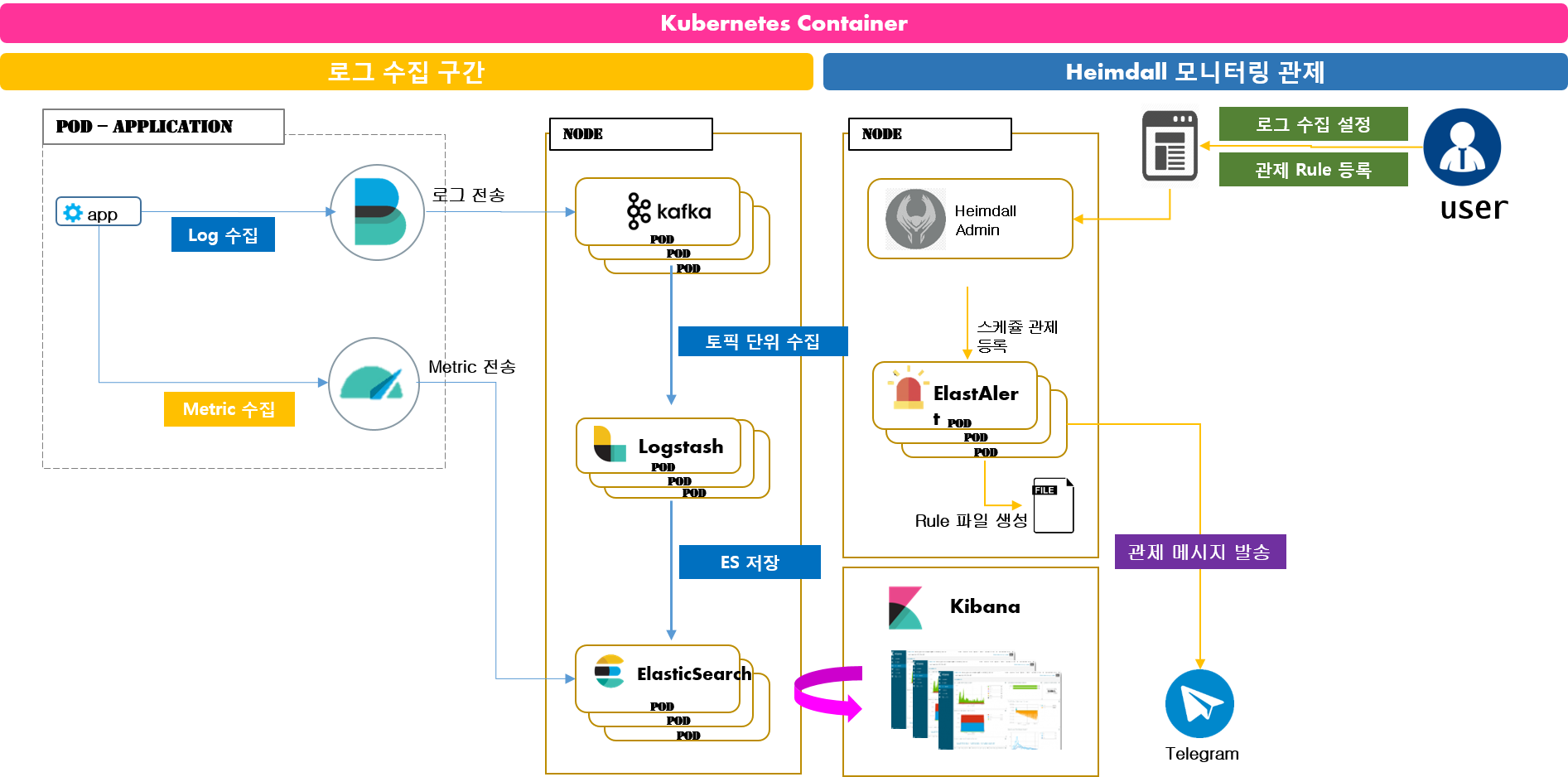 |
| Baremetal 기반 로그 수집 |
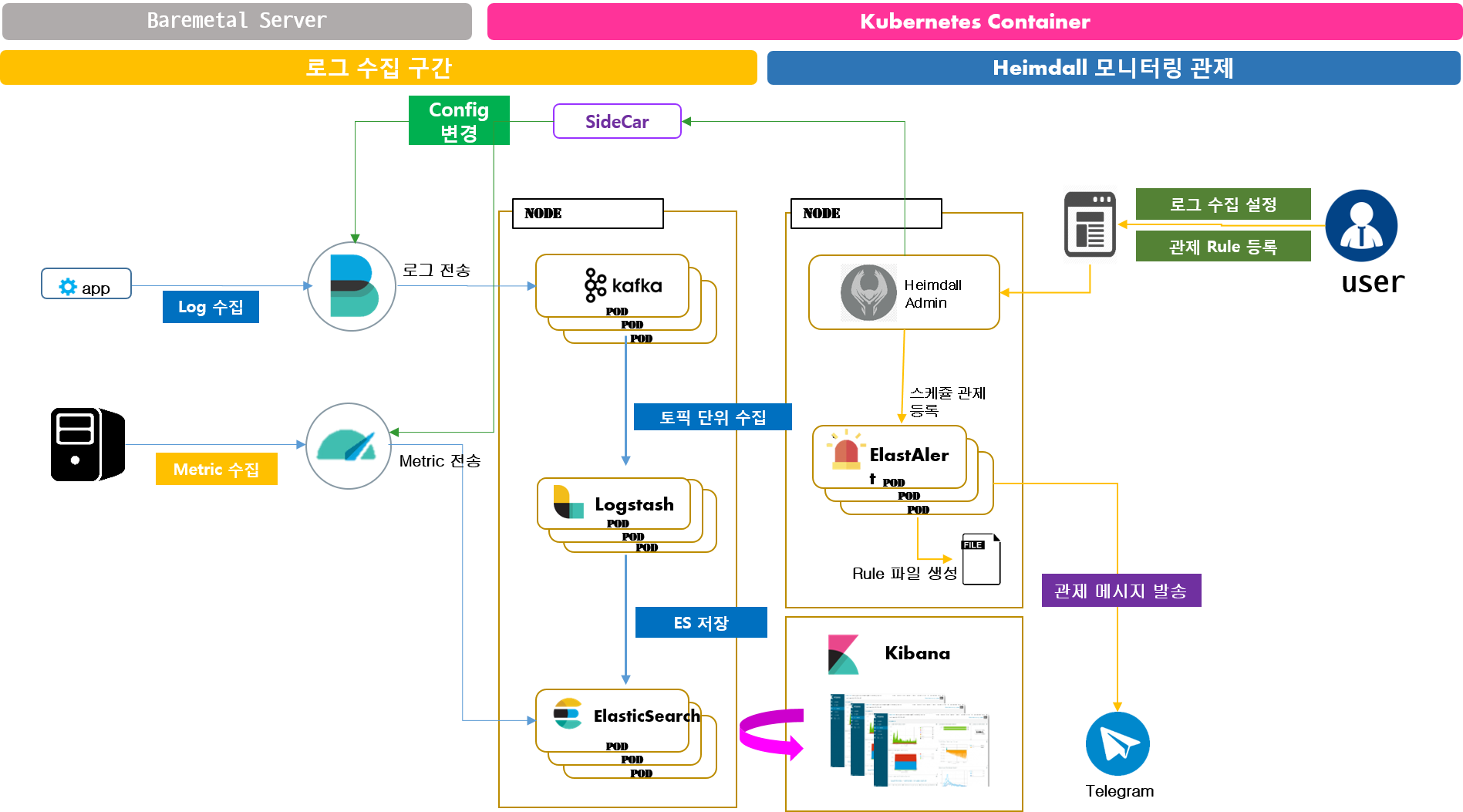 |
2.2. Heimdall 구성 요소 설명
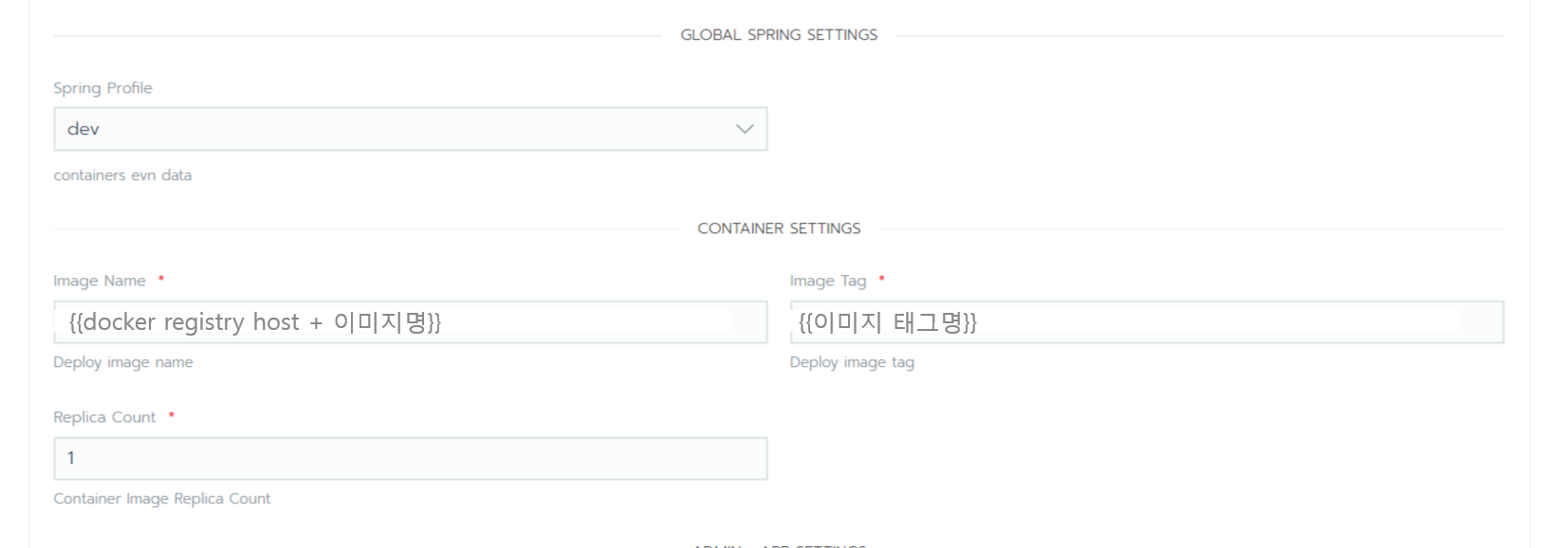
Heimdall Admin
- 로그수집 설정 및 관제에 대한 설정을 관리할 수 있는 페이지입니다.
Filebeat
- 일반적인 로그 수집을 위한 Agent입니다.
Metricbeat
- Metric 정보 수집을 위한 Agent입니다.
Kafka
- Filebeat에서 수집된 로그 데이터의 중간 저장소입니다.
Logstash
- Kafka에서 저장된 로그데이터를 가져와서 로그 패턴에 따라 분리 후 ElasticSearch에 저장해주는 역활을 합니다.
ElasticSearch
- 로그 및 Metric 데이터를 저장하는 저장소입니다.
ElastAlert
- ElasticSearch 저장된 데이터를 기반으로 Telegram으로 관제 메시지를 생성하여 전송해줍니다.
SideCar
- 컨테이너 기반이 아닌 로그수집에 대해서 Filebeat/Metricbeat 설정을 변경할 수 있는 Agent입니다.
Kibana
- ElasticSearch 저장된 데이터를 기반으로 데이터 검색 및 Dashboard 및 그래프등을 표현해줍니다.
3. Heimdall로 어떤것을 할 수 있을까요?
지금까지 Heimdall 관제 시스템이 무엇인지 어떻게 구성되어 있는지 알아보았습니다.
그럼 Heidmall로 무엇을 할 수 있을까요?
3.1. 어플리케이션 로그 수집 및 관제 활용 사례
여러 대의 서버에 어플리케이션 설치되어 있고, 로그파일 경로는 /home/platform/data/lets_agent_avatar/logs/app.log이라고 할때, 해당 서비스에 에러나 정상처리 유무를 확인하려고 한다면 가정해봅시다. 어떻게 확인하게 될까요? 1. 어플리케이션이 6대의 서버에 설치되어 동작되고 있다면 모든 서버에 접근해야 할 것입니다. 2. 서버에 접근 후 로그파일이 위치한 디렉토리에 이동 후 모든 로그파일 열고 3. 어떤 서버에서 문제가 있는지 VI 검색이나 OS 명령어를 통해서 에러가 발생된 로그를 찾아야 할 것입니다. 위에 과정이 번거롭다고 느껴지지는 않나요? 어떻게 이 과정을 쉽게 할 수 있을까요? Heimdall을 사용하면 서버에 직접 접근하지 않아도 특정 로그를 수집할 수 있습니다. 6대의 서버에서 수집된 로그는 ElasticSearch에 날짜별로 특정 인덱스에 통합하여 저장되면 Kibana를 사용하여 모든 로그를 한 곳에서 검색이 될 수 있습니다. 또 이 로그들을 각각의 수치/그래프/DataTable 등 다양한 형태로 표현하고 Dashboard를 생성하면 한 곳에서 한 눈에 원하는 정보를 확인할 수 있습니다. 아래 사용 사례를 정리해놨습니다.
1) 어플리케이션 서버에 Sidecar 설치
Sidecar를 설치하면 로그 수집을 위한 Filebeat/Metricbeat이 설치되고 로그 수집에 관련한 기본 설정이 자동으로 설정됩니다.
Heimdall Admin에서 설정한 정보는 Sidecar를 통해서 서버에 설치된 Filebeat/Metricbeat에 반영되게 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
STEP1. 설치 파일 다운로드
$ wget heimdall.sidecar-0.0.2.tar.gz
$ wget heimdall.sidecar-install-systemctl.sh
$ wget heimdall.sidecar-install-init.sh
STEP2. Sidecar 설치
# centos 7.x 일경우
$ sh heimdall.sidecar-install-systemctl.sh {version} {dev|prod}
{version} : 배포 버전 정보
{dev|prod} : 개발기 dev , 운영기 prod 설정
ex) sh heimdall.sidecar-install-systemctl.sh 0.0.2 dev # 설치 후 확인
# centos 6.x 일 경우
$ sh heimdall.sidecar-install-init.sh {version} {dev|prod}
{version} : 배포 버전 정보
{dev|prod} : 개발기 dev , 운영기 prod 설정
ex) sh heimdall.sidecar-install-init.sh 0.0.2 dev # 설치 후 확인
2) Heimdall Admin 화면에서 로그 수집 설정
| STEP1. 로그 수집 서버 지정 |
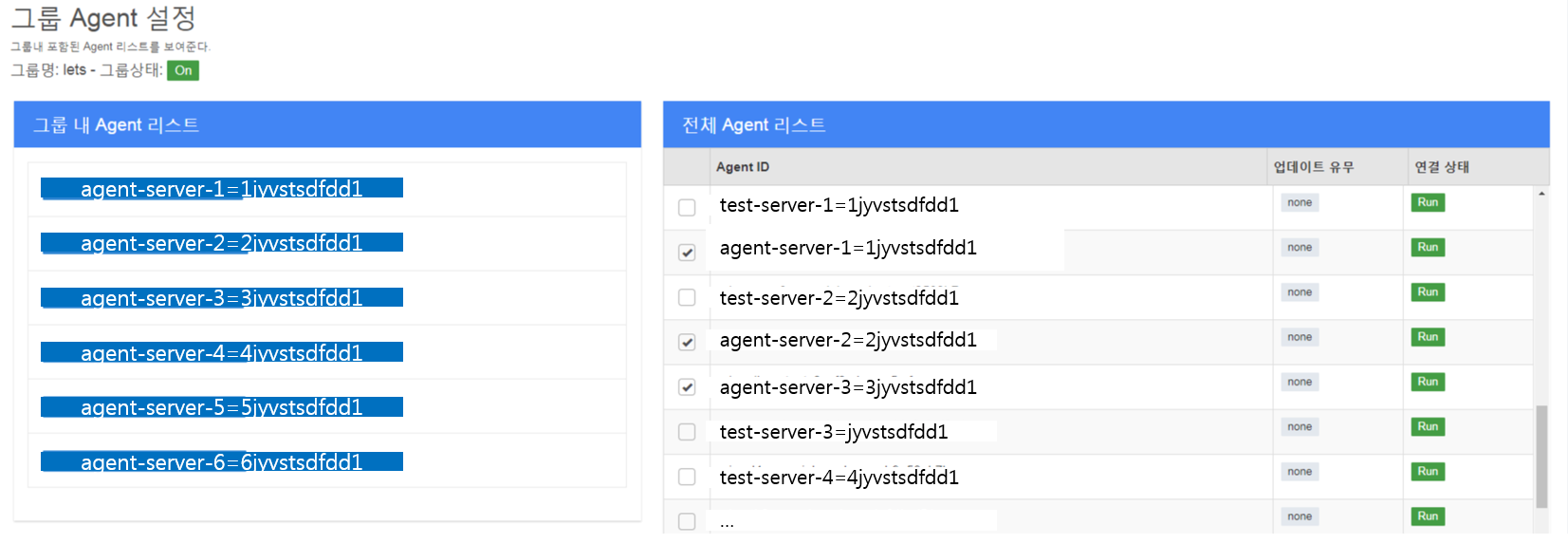 |
| STEP2. 로그 수집 설정 - 수집할 로그 파일 경로를 지정한다. |
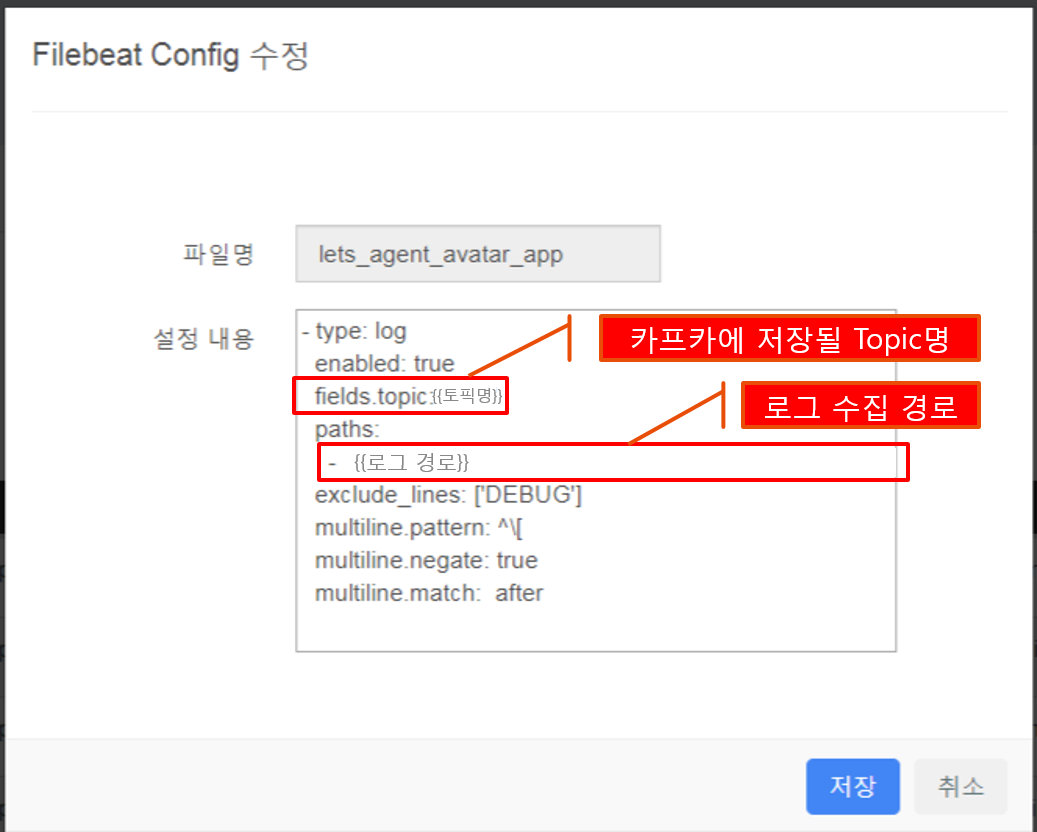 |
3) Logstash에서 로그 내용 가공 Logstash에서는 로그에 대해서 크게 3가지로 분리되어 처리됩니다.
- Input Kafka와 연동하여 Topic 단위로 로그를 가져옵니다.
- Filter
Filter 설정 부분에서 로그의 각 라인은 규칙에 맞게 필드로 분리되어 집니다.
ex) total : {NUMBER:total} : total : 문자열 뒤에 오는 건 number type의 값이고, 이 값을 total이란 필드에 저장하겠다는 의미입니다. - Output ElasticSearch를 연동하여 로그를 저장합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
input {
kafka {
bootstrap_servers => "kafka-host-1, kafka-host-2, kafka-host-3"
topics => ["토픽명"]
codec => "json"
consumer_threads => 3
}
}
filter {
if "app" in [log][file][path] {
grok {
match => {
"message" => [
"\[%{TIMESTAMP_ISO8601:logdate}\] \[%{WORD:loglevel}%{GREEDYDATA:classpath}\] campaign:%{GREEDYDATA:id}, group:%{GREEDYDATA:groupId}, netpoin:%{NUMBER:netpion}, avatar:%{NUMBER:avatar}, seq:%{NUMBER:seq}, size:%{NUMBER:size}, time:%{GREEDYDATA:db_insert_time} - %{GREEDYDATA:result}",
"\[%{TIMESTAMP_ISO8601:logdate}\] \[%{WORD:loglevel}%{GREEDYDATA:classpath}\] campaign:%{GREEDYDATA:id}, group:%{GREEDYDATA:groupId}, netpoin:%{NUMBER:netpion}, mailSeq:%{NUMBER:mailSeq}, memIdx:%{NUMBER:memIdx}, seq:%{NUMBER:seq}, time:%{GREEDYDATA:db_insert_time} - %{GREEDYDATA:result}",
"\[%{TIMESTAMP_ISO8601:logdate}\] \[%{WORD:loglevel}%{GREEDYDATA:classpath}\] Complete Summary id : {GREEDYDATA:SummaryId}, total : {NUMBER:total}, success : {NUMBER:success}, filtered : {NUMBER:filtered}, missing : {NUMBER:missing}, induceSuccess : {NUMBER:induceSuccess}, error: {NUMBER:error} campaign:%{GREEDYDATA:id}, group:%{GREEDYDATA:groupId}, netpoin:%{NUMBER:netpion}, mailSeq:%{NUMBER:mailSeq}, memIdx:%{NUMBER:memIdx}, seq:%{NUMBER:seq}, time:%{GREEDYDATA:db_insert_time} - %{GREEDYDATA:result}"
]
}
}
}
else {
grok {
match => [
"message", "\[%{TIMESTAMP_ISO8601:timestamp}\] \[%{LOGLEVEL:log-level} %{GREEDYDATA:classpath}\] %{GREEDYDATA:msg}"
]
}
}
ruby {
code => "event.set('index_date', Time.now());"
}
ruby {
code => "event.set('index_day', event.get('[@timestamp]').time.localtime.strftime('%Y.%m.%d'));event.set('kafka_in_time',event.get('[@timestamp]'));event.set('@timestamp',event.get('index_date'))"
}
}
output {
elasticsearch {
hosts => ["{{elasticsearch 호스트}}:9200"]
index => "filebeat-sri-%{[@metadata][topic]}-%{index_day}"
}
}
4) 로그 데이터 검색
- 3번 단계에서 처리된 로그는 ElaistcSearh에서 filebeat-sri-%{[@metadata][topic]}-%{index_day}로 인덱스가 생성되어 저장됩니다.
- 이렇게 수집된 수집된 로그는 Kibana 통하여 검색할 수 있습니다.
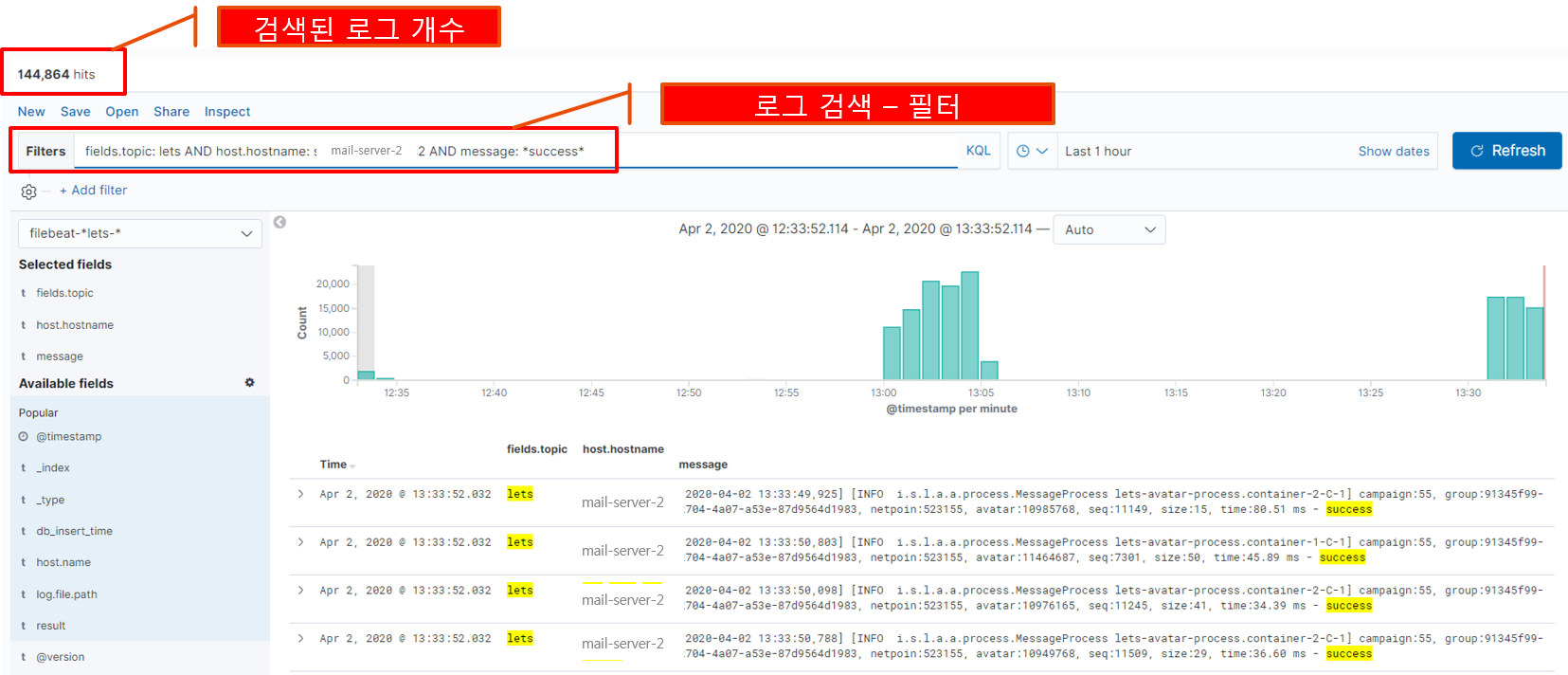
아래는 검색에 대한 예제입니다.
토픽명이 lets이면서 sri-mail-content2번 서버에 수집된 로그를 기준으로 검색하면서,
로그 메시지 내용에 sucess가 포함된 것만 검색하겠다고 조건식을 작성하여 나온 결과입니다.
로그 시간 범위는 최근 한 시간동안 수집된 로그에 대해서만 포함되게 지정하였습니다.
5) Dashboard를 구성해보자
- 로그 내용을 기반으로 검색은 4번 방법으로도 충분하다.
- 그렇지만 예를 들어 30분 단위의 DB Insert 개수를 보여주는 수치인 경우 검색보다는 DashBoard를 구성하여 그래프를 보여주는 방법이 더욱 효과적일 것입니다.
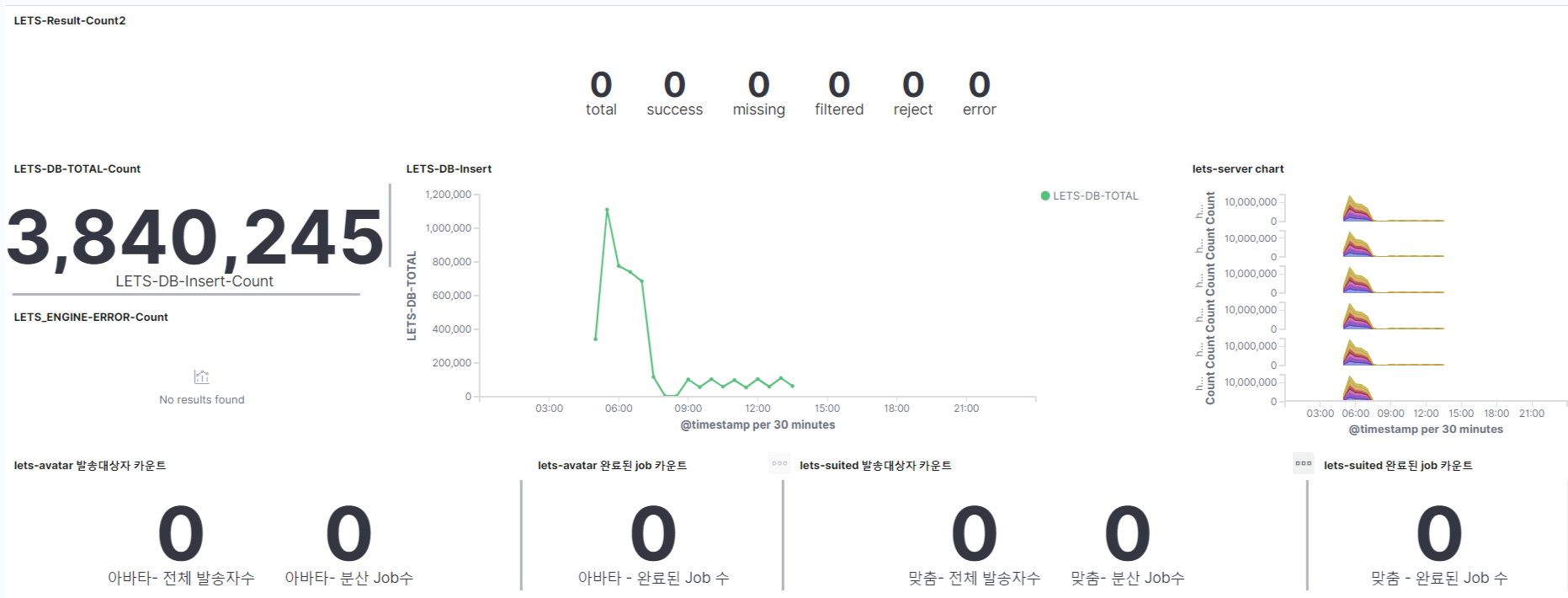
다음과 같이 Dashboard를 구성할 수 있습니다.
Lets-Result-Count2 : 총 발송 개수에서 성공/실패등을 수치를 숫자로 표시
Lets-Db-Total-Count : 총 DB Insert 개수를 숫자로 표시
Lets-DB-Insert : 30분 단위로 DB Insert 개수를 Line Graph로 표시
Lets-server chart : 서버별로 수집된 로그 개수를 30분 단위로 표시
..생략..
6) 관제 알림
- 어플리케이션 에러가 발생된 경우 개발자에게 해당 내용을 통지해야 최소한의 서비스 장애나 중단으로 처리가 될 것입니다.
- Heimdall에서는 ElastAlert을 사용하여 관제 조건을 설정하고, 에러가 발생 시 Telegram으로 통지하는 기능을 제공합니다.
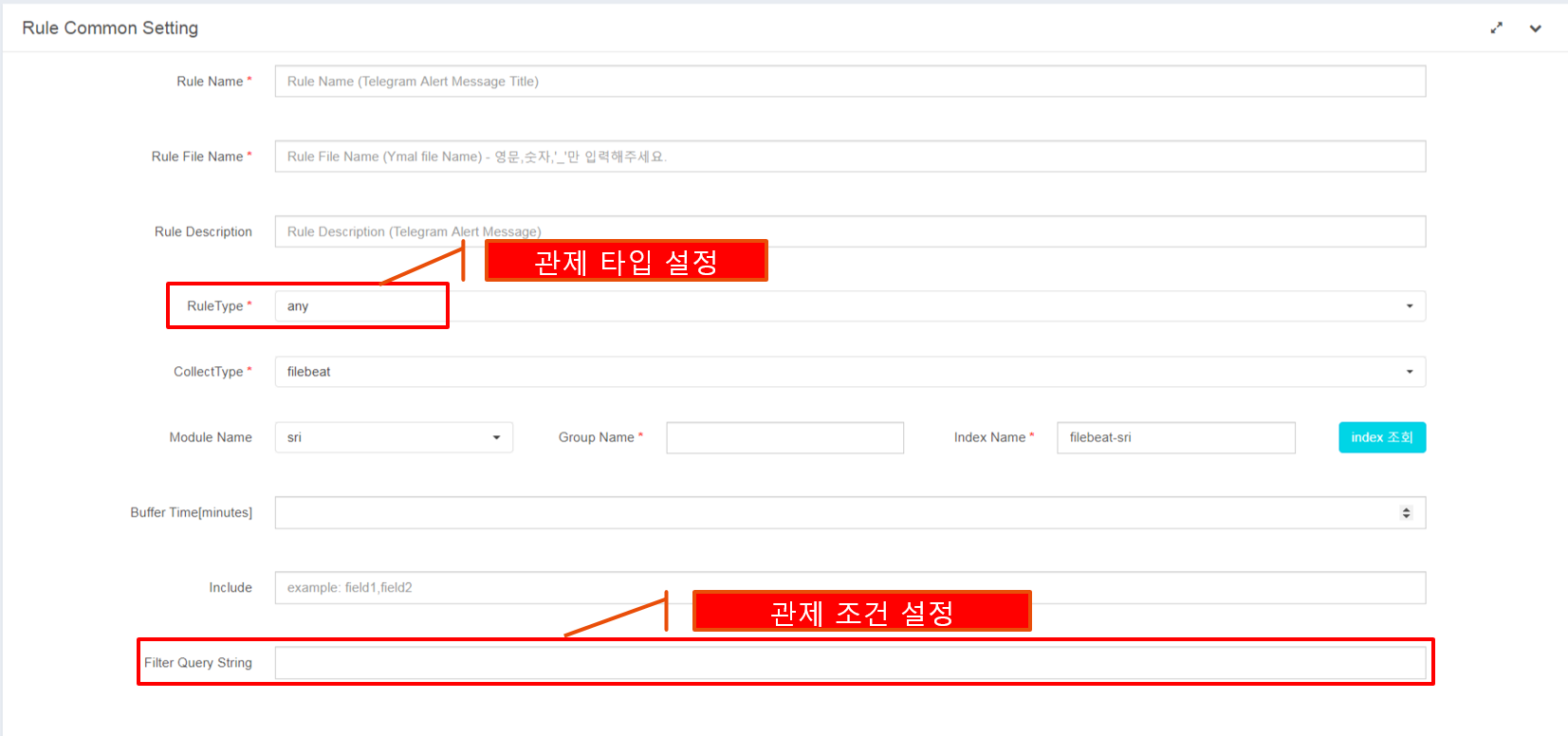
- 관제 알림에 대한 설정은 Heimdall Admin에서 추가할 수 있습니다.
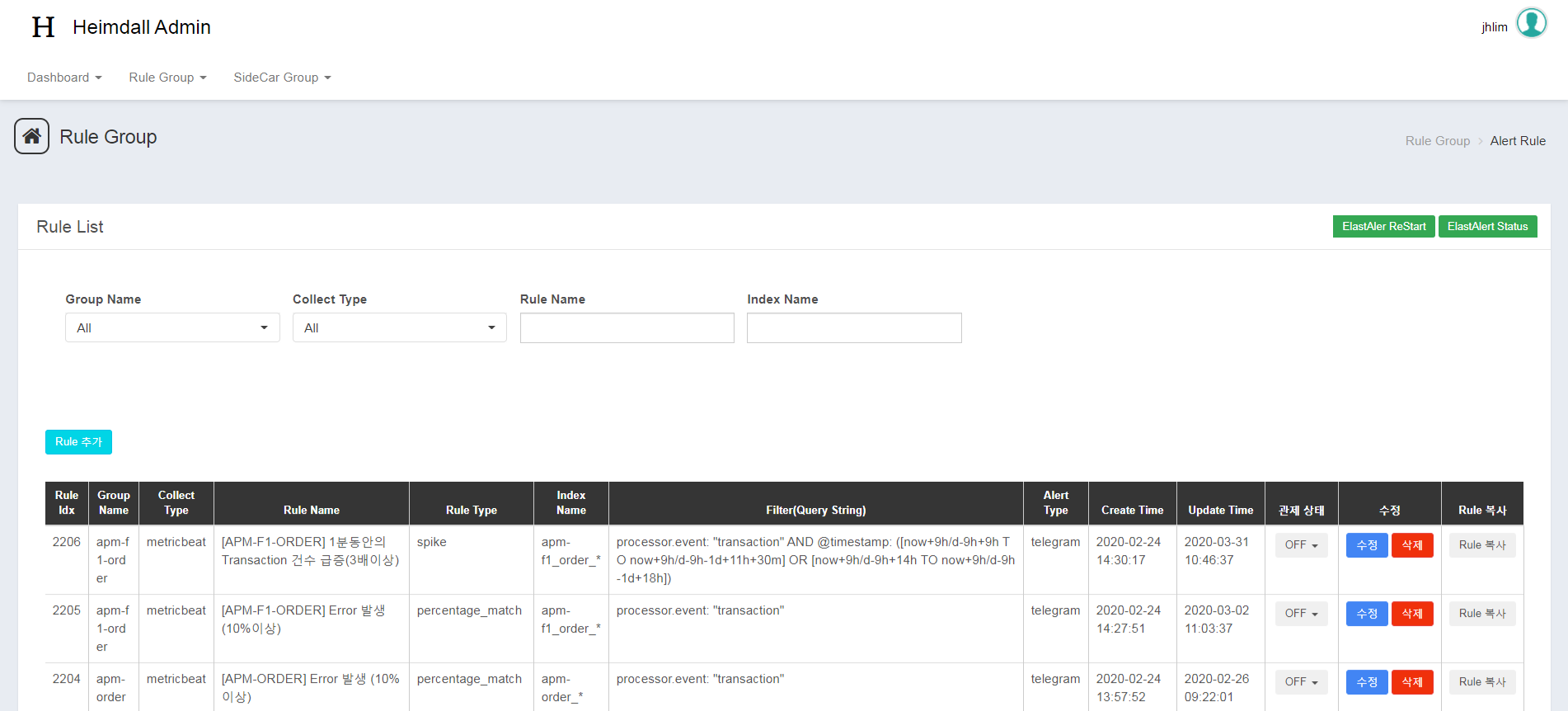
| STEP1. 관제 Rule 추가 |
 |
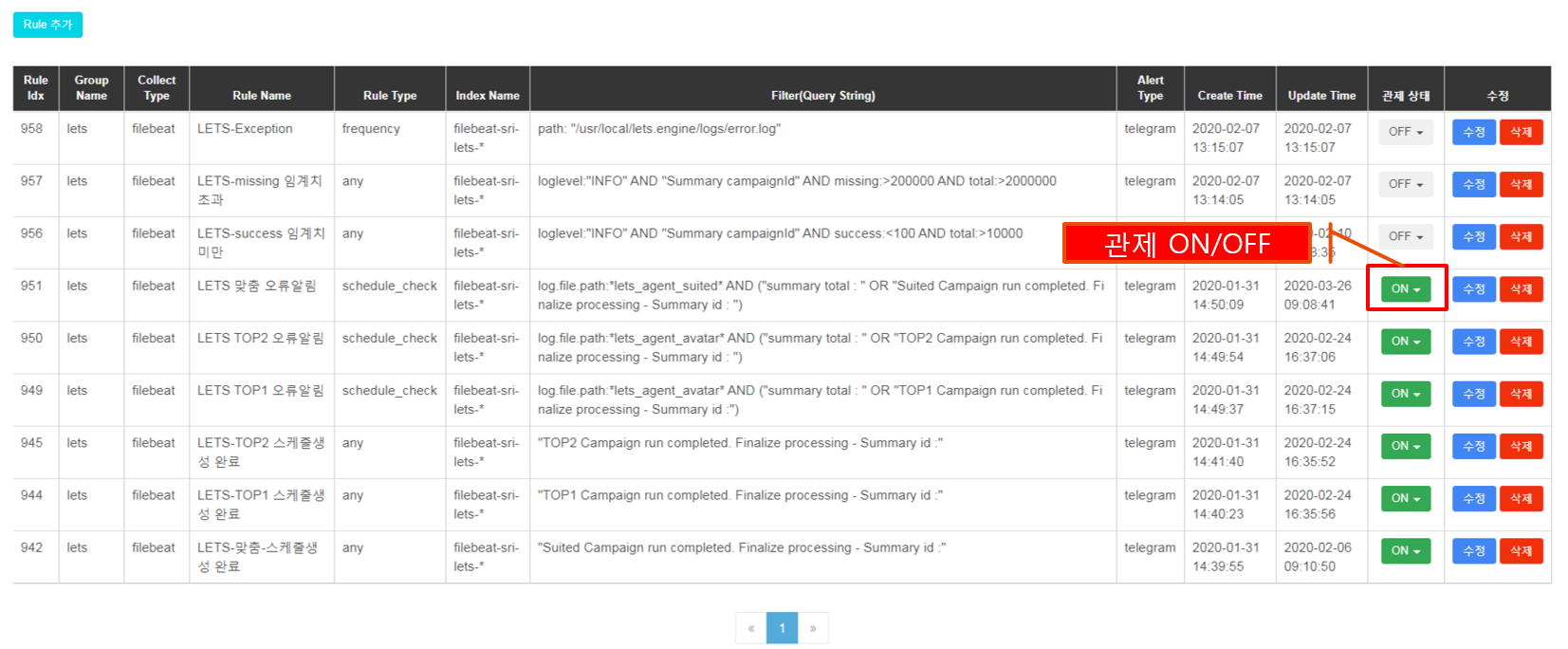
| STEP2. 관제 추가 후 목록에서 관제 기능 ON/OFF 지정도 가능 |
 |
| STEP3. 관제 발생 시 Telegram으로 메시지 전송 |
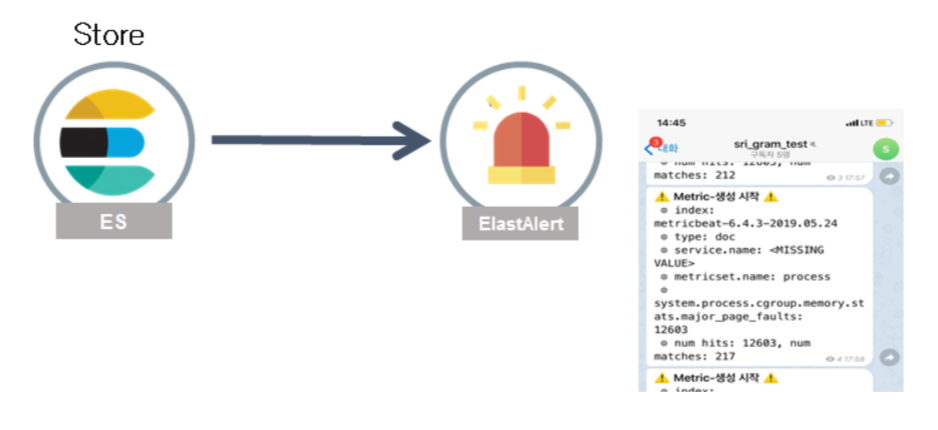 |
3.2. Metric 수집을 활용한 Kafka 상태 정보 확인
서버에 어플리케이션에 연동된 DB, Kafka, Redis가 갑자기 중지되어 장애가 발생된 경험을 한 적 없으신가요? Heimdall에서는 이런 연동 모듈에 대해서 상태 정보를 수집하여 다양한 정보를 제공합니다.
1) 어플리케이션 서버에 Sidecar 설치
- 3.1 내용과 동일합니다
2) Heimdall Admin 화면에서 Metric 수집 설정
| STEP1. 로그 수집 서버 지정 |
|
| STEP2. Metric 수집 설정 - 수집할 Metric 모듈에 대한 설정 |
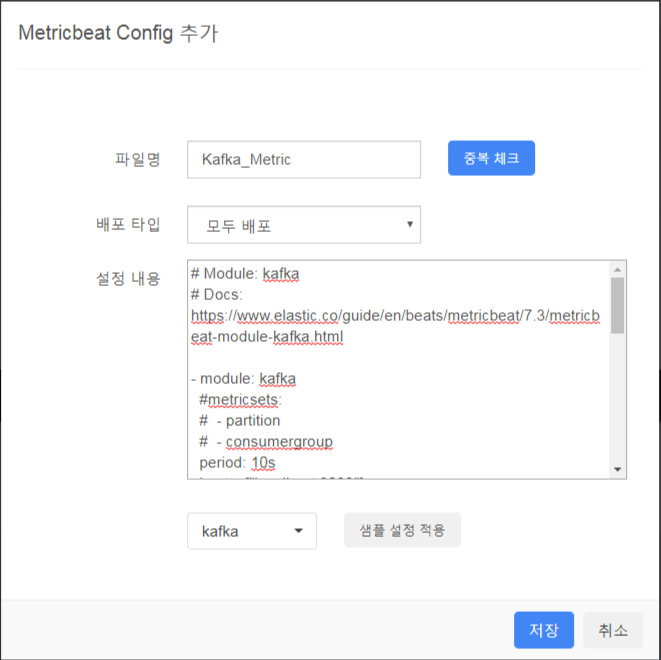 |
3) Metric 데이터 검색
- Metric 정보는 Kafka, Logstash를 거치지 않고 ElasticSearh에서 metricbeat-kafka-* 인덱스가 생성되어 저장됩니다.
- 이렇게 수집된 수집된 로그는 Kibana 통하여 검색할 수 있습니다.
Kafka에서 수집된 정보는 metricset 별로 분리되어 수집됩니다.
그럼 예제로 kafka partition에 대해서만 필터링해서 검색해보죠
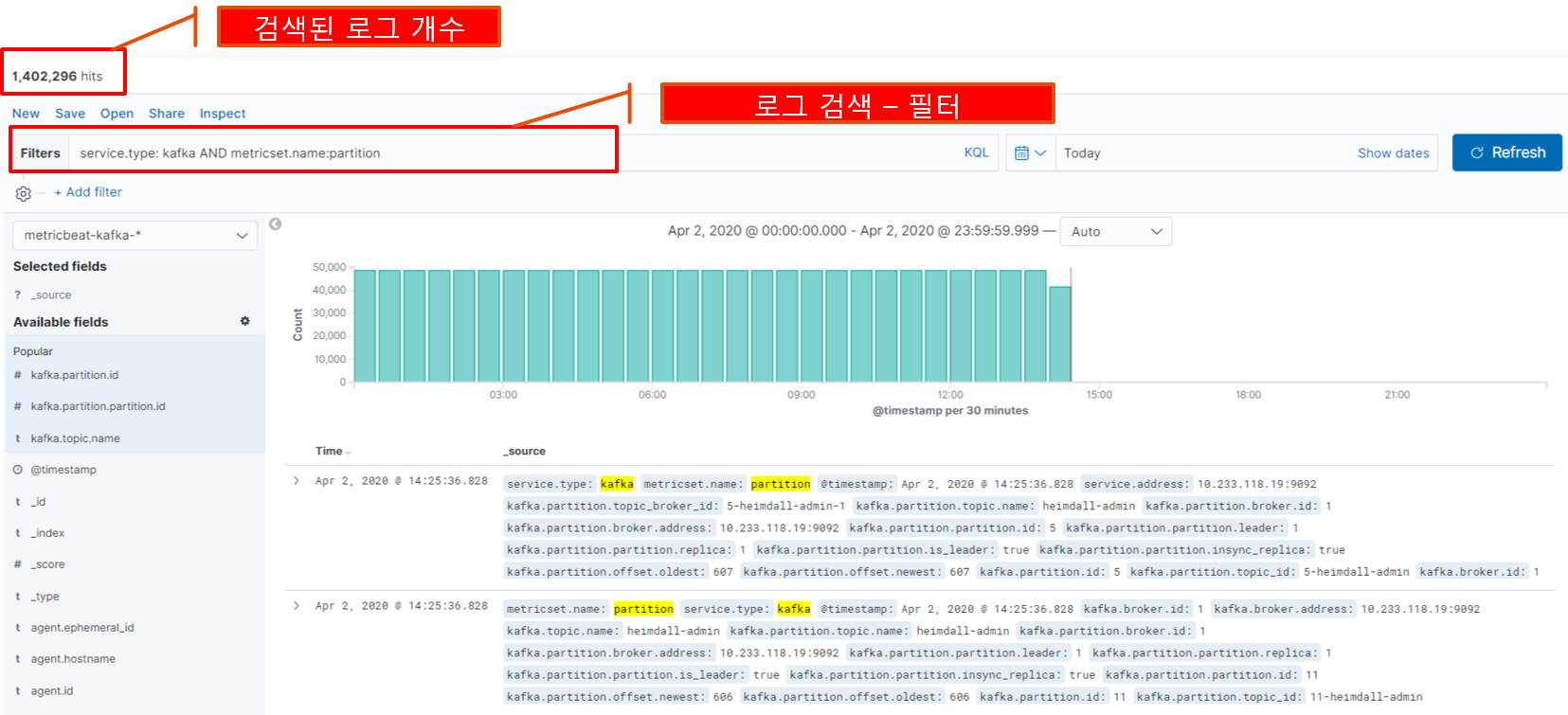
4) Metric Dashboard
1
2
3
4
5
6
Kafka Dashboard 구성 예제입니다.
[SRI]Kafka Cluster Selector : select box를 사용하여 조건별로 필터링 기능을 제공
Kafka Metrics : 카프카의 topics, partions 개수를 숫자로 표시
Consumer Group Lag by Topic : Topic에 데이터가 쌓이게 되면 Lag 수치가 올라가는데
이 수치를 그래프로 표시
..생략..
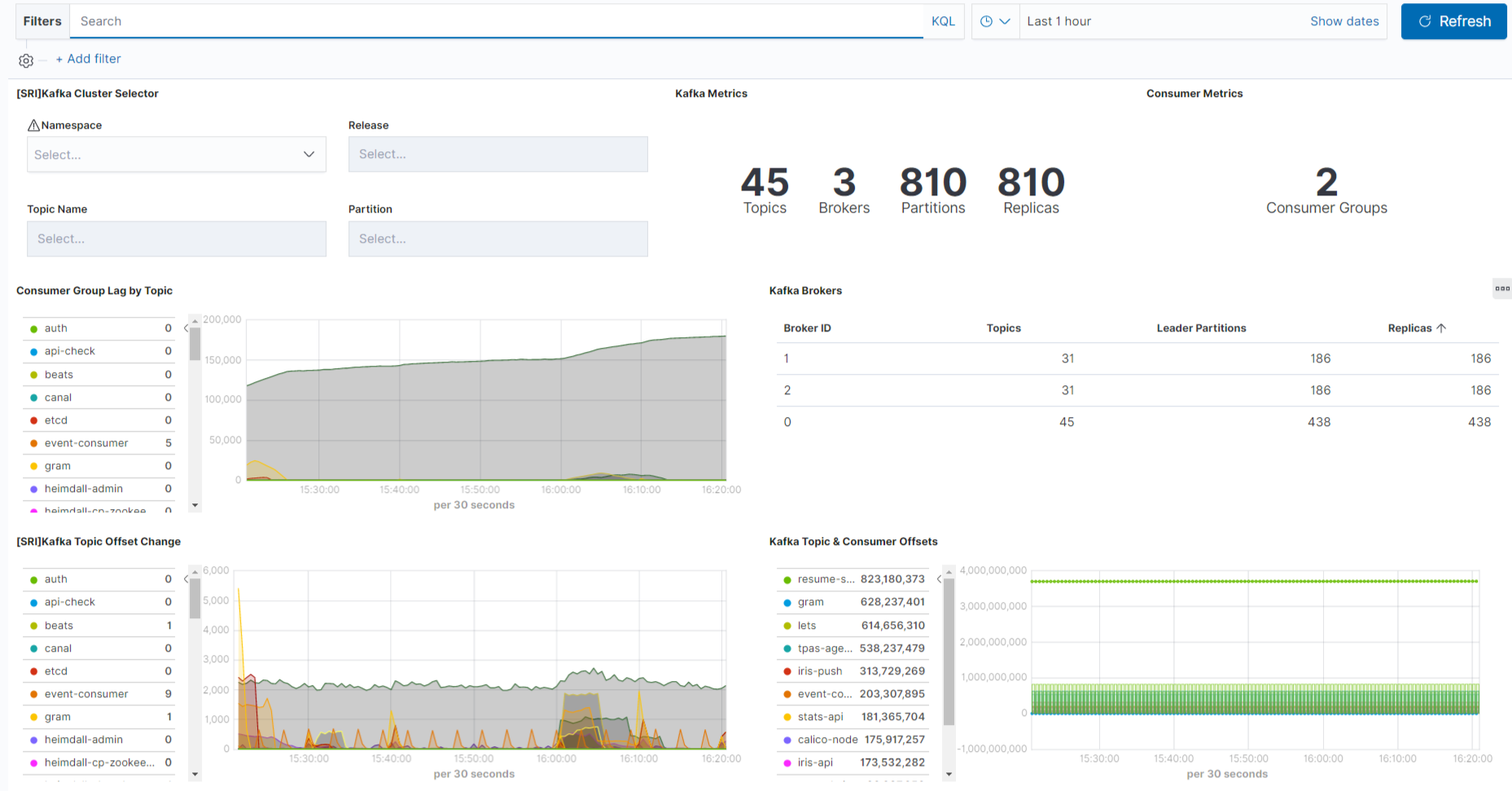
5) 관제 알림
- Metric에 대해서 관제 설정 및 알림 설정이 가능합니다.
- 이 내용은 위에 3.1 내용과 동일합니다
4. Heimdall 시스템 고도화 기능
이 섹터에서는 Heimdall 고도화에 적용된 기술 및 개선 내용에 대해서 설명하겠습니다.
4.1. Heimdall 관리자 화면 UI 개선
- spring boot 최신 버전으로 변경
- 최신 기술을 반영하면 전체적인 패키지 구조 및 리팩토링 진행
- mustache -> thymeleaf 템플릿으로 변경
- Thymeleaf Layout 구성으로 전체적인 화면 구조 재구성
- 공통모듈 분리로 확장성 고려
- 서비스 구조를 그룹 구조로 분리하여 검색 및 관리에 대한 화면 및 기능 개선
- 메뉴화면 추가
- Group 구조로 관리되어 필터링 및 관리 개선
- Path 연동
- 로그인 기능 추가
- 사용자 요청 별 권한 관리 처리
| 기존 관리자 화면 |
 |
| 신규 관리자 화면 |
 |
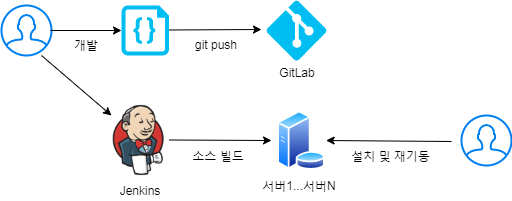
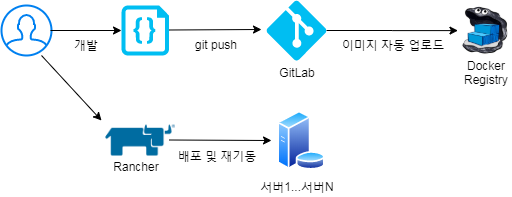
4.2. Gitlab/Docker/Kubernetes/Rancher 기반의 배포로 변경
쿠버네티스 환경으로 Heimdall 시스템을 이관하면서 배포환경도 변경되었습니다.
| 기존. Jenkins 기반 배포 | 변경. Rancher 기반 배포 |
 |
 |
4.2.1 기존의 소스 배포 흐름
- 기존 배포의 경우 Jenkins를 활용한 배포 방법은 다음과 같은 과정을 거치게 됩니다.
git -> jenkins build -> 각 서버 접속 -> 어플리케이션 중지 -> install.sh 설치 -> 어플리케이션 기동 및 확인 - 모든 서버에 들어가서 위에 단계를 반복하게 됩니다.
4.2.2 변경된 소스 배포 흐름
- 일반 서버의 배포라면 Jenkins 사용한 배포도 나쁘지 않다고 생각합니다.
- 그러나 Kubernetes 환경이라면 이미지 배포에서 Rancher를 사용하여 좀 더 편한게 진행할 수 있습니다.
1) 소스 수정 및 git commit & push
2) gitlab에서 소스 변경 시 docker build를 수행 후 docker regstiry 서버에 이미지를 업로드 해줍니다.
- gitlab-ci.yml 설정 파일
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
stages:
- compile
- build
- push
- deploy
variables:
CI_REGISTRY: {{docker registry 주소}}
BUILD_TAG: $CI_COMMIT_REF_NAME-$CI_PIPELINE_ID
GIT_SUBMODULE_STRATEGY: recursive
.gram-runner: &tag_def
tags: [gram]
compile:
<<: *tag_def
stage: compile
script:
- gradle clean build
build admin:
<<: *tag_def
variables:
GIT_STRATEGY: none
stage: build
script:
- > # admin build
docker build
-t $CI_REGISTRY:$BUILD_TAG .
-f {{Dockerfile 경로}}
push tag:
<<: *tag_def
variables:
GIT_STRATEGY: none
stage: push
script:
- docker push $CI_REGISTRY:$BUILD_TAG
Push latest:
<<: *tag_def
variables:
GIT_STRATEGY: none
stage: push
only:
- master
script:
- docker tag $CI_REGISTRY:$BUILD_TAG $CI_REGISTRY:latest
- docker push $CI_REGISTRY:latest
when: manual
3) rancher 서버에 접속 후 이미지 버전만 변경하고 적용하면 기존 이미지 버전의 어플리케이션이 내려가고 새로운 이미지 버전으로 어플리케이션을 자동으로 기동해줍니다.
4) Admin이 배포되어 기동된 것을 확인할 수 있습니다.
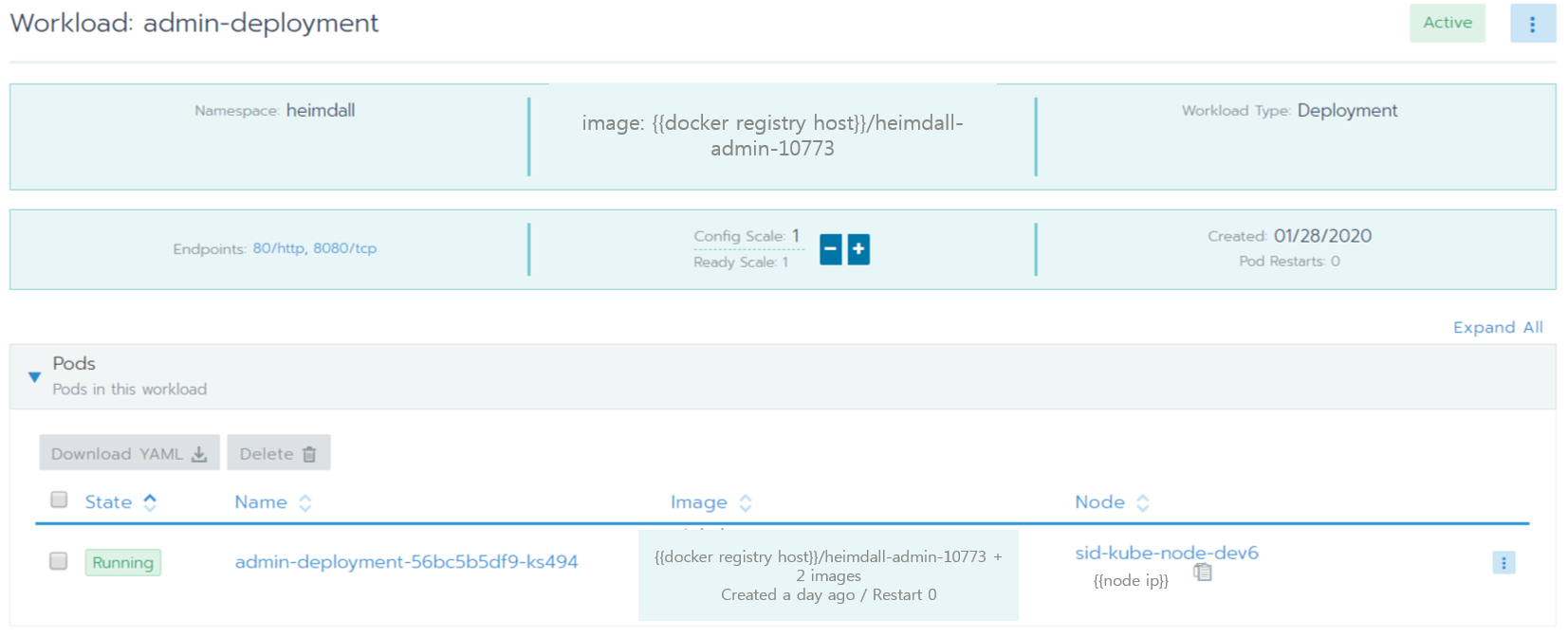
4.3. 모니터링/관제 개선
4.3.1. 로그 처리 구조 개선
1) 로그 수집 처리 변경
| 기존 로그 수집 구조 : Logstash -> ElasticSearch |
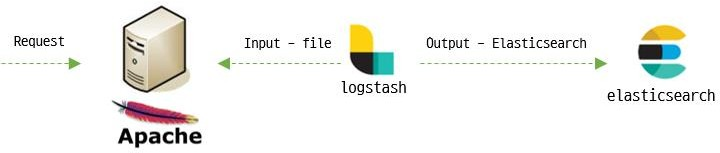 |
문제점1. Logstash 지연 및 성능 이슈
- 로그에 대한 수집과 로그 문자열 분리 작업을 모두 처리하게 되어서 부하가 발생
- 이로 인하여 성능 저하와 로그 유실이 발생되었습니다.
문제점2. 로그 파일 관리 문제
- Logstash 설정 파일 하나에서 여러개의 로그 파일을 관리하기 때문에
- 로그파일이 증가될 때마다 내용도 길어지고,
- 조건식 분기 구문이 늘어나는 구조여서 관리가 힘들었습니다.
| 개선된 로그 수집 구조 : Filebeat -> Kafka -> Logstash -> ElasticSearch |
 |
개선1. 로그 수집 분리
- Logstash의 파일 수집에 대해서 Filebeat(경량 로그 수집)로 이관하고,
- Filebeat과 Logstash 사이에 중간 버퍼 역활을 위한 Kafka를 구성하여
- Logstash의 부하를 줄이므로써 로그 지연 및 성능을 개선하였습니다.
개선2. 로그 파일 관리 개선
- Filebeat에서 로그 개수에 따라 설정 파일을 분리해서
- 로그 관리가 수월해졌습니다.
4.3.2. 로그 처리
기존 관제시스템은 서버 기반 로그 수집만 가능했습니다.
Heimdall 관제시스템은 K8S 컨테이너 기반의 로그수집과 Baremetal Server 기반의 기존 로그수집 모두 가능하게 변경하였습니다.
Baremetal Server 기반의 기존 로그수집은 위에 “3.1 어플리케이션 로그 수집 및 관제 활용 사례”에서 언급을 했으니 이번 섹터에서는 “K8S 컨테이너 기반 로그 수집”에 대해서 설명하겠습니다.
1) K8S 컨테이너 기반의 로그수집 과정
- 컨테이너 기반 로그 수집은 Baremetal Server 방식에서 사용되던 Sidecar를 통한 로그 수집이 아닌 어플리케이션 내부에서 Filebeat이 Sidecar 형태로 로그를 수집하는 구조입니다.
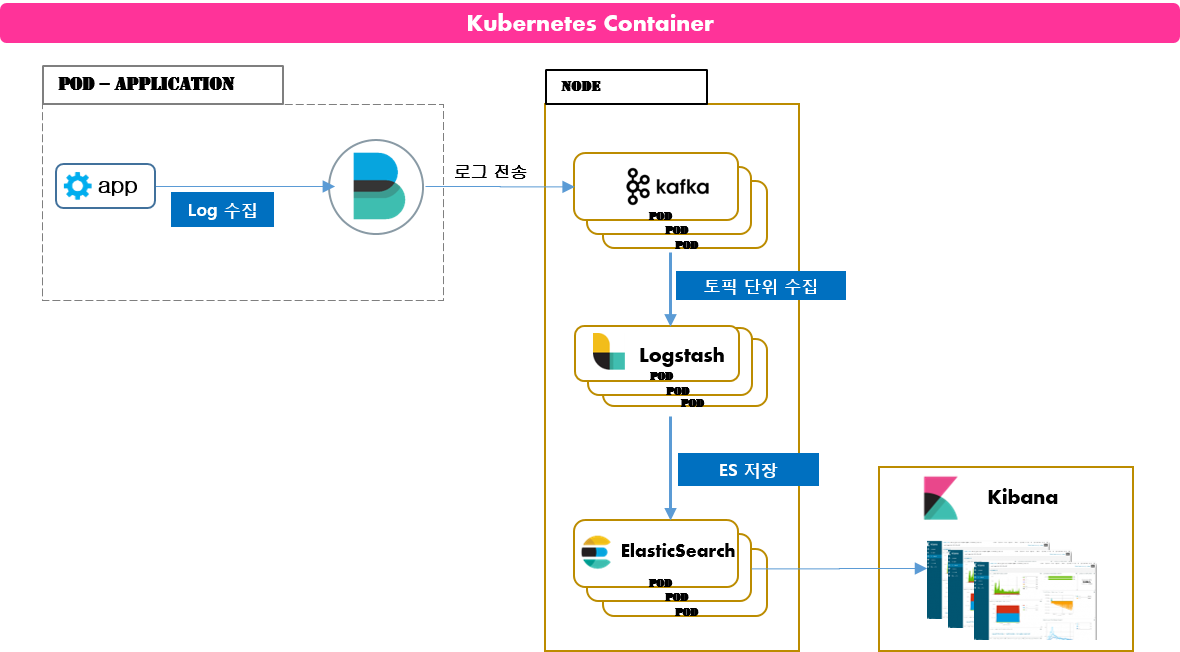
1-1) Rancher에서 설정
- Rancher + Helm Chart를 사용하여 컨테이너 로그 수집에 대한 ON/OFF를 설정하게 했습니다.
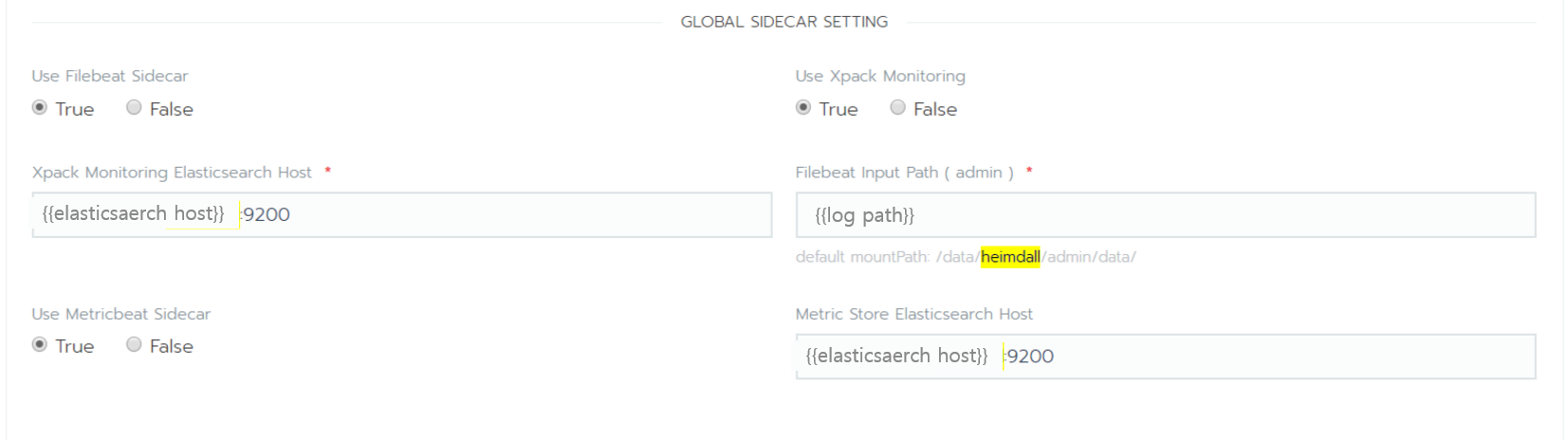
1-2) K8S 컨테이너 - Filebeat 설정 참고
- 어플리케이션과 로그수집을 위한 Filebeat이 하나의 Pod로 구성이 되며,
- Filebeat은 Sidecar 형태로 배포되어 어플리케이션 로그를 수집하게 됩니다.
- 아래는 Filebeat 설정을 위한 Helm Chart 내용입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ .Release.Name }}-{{ include "heimdall.name" . }}-filebeat-config
data:
filebeat.yml: |-
filebeat.config:
inputs:
path: ${path.config}/inputs.d/*.yml
reload.enabled: true
reload.period: 30s
modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: true
reload.period: 30s
processors:
- add_locale: ~
- add_fields:
fields:
sri.namespace: '${SRI_NAMESPACE}'
sri.project.name: '${SRI_PROJECT_NAME}'
sri.release.name: '${SRI_RELEASE_NAME}'
sri.server.name: '${SRI_POD_NAME}'
monitoring:
enabled: {{ .Values.global.sidecar.filebeat.monitor }}
elasticsearch:
hosts: ["{{ .Values.global.sidecar.filebeat.esHost }}"]
metrics.period: 30s
output.kafka:
hosts: [{{ .Values.global.sidecar.filebeat.kafkaHost }}]
topic: '${SRI_NAMESPACE}-${SRI_PROJECT_NAME}'
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000
---
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ .Release.Name }}-{{ include "heimdall.name" . }}-filebeat-inputs
data:
{{ConfigMap명}}.yml: |-
- type: log
paths:
- '{{ .Values.sidecar.filebeat.logPath }}'
exclude_lines: ['DEBUG']
tail_files: "true"
## json.message_key: log
## json.keys_under_root: false
multiline.pattern: "^\\["
multiline.negate: true
multiline.match: after
multiline.max_lines: 50
multiline.timeout: 10s
processors:
- add_kubernetes_metadata:
in_cluster: true
1-3) ConfigMap을 통한 Filebeat 설정 관리
- Helm Chart로 배포된 설정은 ConfigMap 형태로 관리가 됩니다.
- 배포 이후에 설정에 변경 시 ConfigMap 부분만 변경하면 어플리케이션의 재기동 없이도 적용이 됩니다.
- 아래는 실제 배포된 내용이입니다.
paths : 수집될 로그 경로
exclude_lines: [‘DEBUG’] : 디버그 로그는 제외하고 수집
multiline : multiline 로그 처리
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- type: log
paths:
- '{{로그 경로}}'
exclude_lines: ['DEBUG']
tail_files: "true"
## json.message_key: log
## json.keys_under_root: false
multiline.pattern: "^\\["
multiline.negate: true
multiline.match: after
multiline.max_lines: 50
multiline.timeout: 10s
processors:
- add_kubernetes_metadata:
in_cluster: true
4.3.3. Metric 로그 수집 추가
Metric 로그 수집 추가는 이번에 고도화를 진행하면서 새롭게 추가된 부분입니다. 어플리케이션에서 문제가 발생하는 경우 로그 수집으로 확인이 가능했지만, 어플리케이션에서 연동되는 서버스가 문제가 되는 경우, 장애에 대한 인지가 늦어 대응이 늦는 경우가 발생되었습니다. 이에 대응하기 위해서 Metric 기반의 로그를 수집하여 정상 기동 및 장애 발생에 대응할 수 있었습니다. 다른 한가지 이유는 Heimdall 시스템 및 기존 어플리케이션을 Kubernetes 환경에서 배포가 진행되면서 Kubernetes에 대한 서비스, 노드, 파드에 대한 관리가 필요하기 때문에 Metric 기반 로그 수집은 중요해졌습니다. MetricBeat은 기본으로 Kubernetes, System에 대한 Metric을 수집하지만 추가적인 모듈 설치로 다양한 Metric 정보를 수집할 수 있다.
1) Metric 로그 수집 과정
- Filebeat 로그 수집과 동일하게 Metric 로그 수집도 Baremetal Server 방식에서 사용되던 Sidecar를 통한 로그 수집이 아닌 어플리케이션 내부에서 Metricbeat이 Sidecar 형태로 Metric 정보를 수집하는 구조입니다.
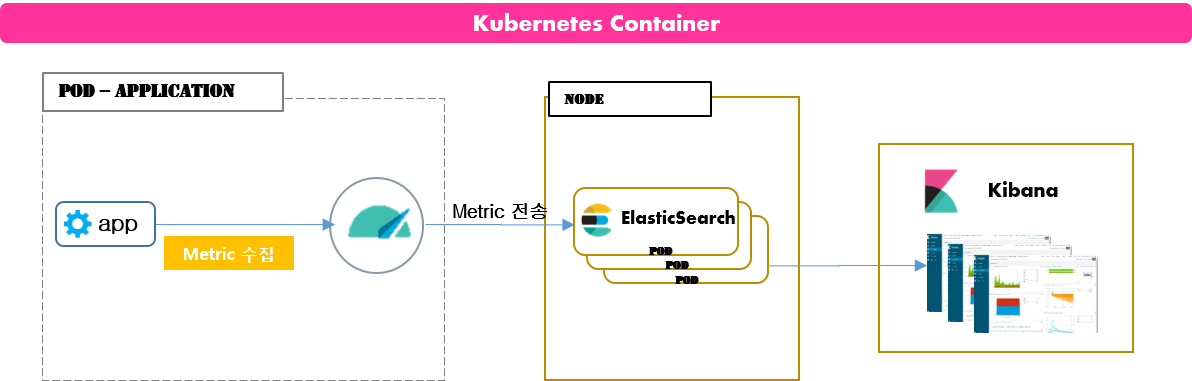
2) Metric 모듈 종류
- MetricBeat은 기본으로 Kubernetes, System에 대한 Metric을 수집하지만 추가적인 모듈 설치로 다양한 Metric 정보를 수집할 수 있다.
- 아래는 수집할 수 있는 모듈 종류입니다. 더 많은 정보는 아래 링크를 참고해주세요. https://www.elastic.co/guide/en/beats/metricbeat/7.3/metricbeat-modules.html
- 참고로 Metric 모듈은 버전이 올라갈 때마 더 많은 연동 모듈이 추가되고 있습니다.
• System
• Kubernetes
• Apache
• Nginx
• Docker
• Elasticsearch
• HAProxy
• Envoyproxy
• Jmx
• Kafka
• Logstash
• MySQL
• Redis
• Zookeeper
• PHP_FPM
......
3) Metric 설정 예제
Metric 로그 수집도 K8S 컨테이너 기반의 로그수집과 Baremetal Server 기반의
기존 로그수집 모두 가능합니다.
1. K8S 컨테이너 기반의 로그수집
Helm Chart에서 작성된 설정파일을 기반으로
Rancher 배포 화면에서 ON/OFF를 지정할 수 있습니다.
로그수집을 ON으로 지정 시 컨테이너 내부에 Sidecar 형식으로 동작됩니다.
2. Baremetal Server 기반의 기존 로그수집
Heimdall Admin에서 Metric 설정 페이지가 추가되었습니다.
Metric 로그 수집을 설정하게 되면 지정된 서버에 설치된 Sidecar Agent를 통해서
Metricbeat 통해서 수집이 진행됩니다.
Baremetal Server 기반의 기존 로그수집은
위에 "3.1 어플리케이션 로그 수집 및 관제 활용 사례"에서 언급을 했으니
이번 섹터에서는 "K8S 컨테이너 기반 Metric 로그 수집"에 대해서 설명하겠습니다.
3-1) K8S 컨테이너 기반의 Metric 로그 수집
1) Rancher에서 설정
- Rancher + Helm Chart를 사용하여 컨테이너 로그 수집에 대한 ON/OFF를 설정하게 했습니다.
2) K8S 컨테이너 - Metricbeat 설정 참고
- 어플리케이션과 로그수집을 위한 Metricbeat이 하나의 Pod로 구성이 되며,
- Metricbeat은 Sidecar 형태로 배포되어 설정된 모듈을 기반으로 Metric 정보를 수집하게 됩니다.
- 아래는 Metricbeat 설정을 위한 Helm Chart 내용입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ .Release.Name }}-{{ include "heimdall.name" . }}-metricbeat-config
labels:
kubernetes.io/cluster-service: "true"
data:
metricbeat.yml: |-
metricbeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: true
reload.period: 30s
processors:
- add_locale: ~
- add_kubernetes_metadata:
in_cluster: true
- add_fields:
fields:
sri.namespace: '${SRI_NAMESPACE}'
sri.project.name: '${SRI_PROJECT_NAME}'
sri.release.name: '${SRI_RELEASE_NAME}'
sri.server.name: '${SRI_POD_NAME}'
monitoring:
enabled: true
elasticsearch:
metrics.period: 30s
output.elasticsearch:
hosts: ["{{ .Values.global.sidecar.metricbeat.esHost }}"]
index: 'metricbeat-%{[event.module]}-${SRI_NAMESPACE}-${SRI_PROJECT_NAME}-%{+yyyy.MM.dd}'
setup.template:
enabled: true
name: 'metricbeat-sri'
pattern: 'metricbeat-*'
setup.ilm:
enabled: false
---
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ .Release.Name }}-{{ include "heimdall.name" . }}-metricbeat-module
data:
jolokia_metric.yml: |-
- module: jolokia
enabled: true
metricsets: ["jmx"]
namespace: "jmx"
hosts: ["localhost:8778"]
path: "/jolokia"
http_method: "GET"
jmx.mappings:
- mbean: 'java.lang:type=Runtime'
attributes:
- attr: Uptime
field: uptime
- attr: StartTime
field: starttime
- mbean: 'java.lang:type=OperatingSystem'
attributes:
- attr: ProcessCpuLoad
field: processcpuload
- attr: ProcessCpuTime
field: processcputime
- mbean: 'java.lang:type=Memory'
attributes:
- attr: HeapMemoryUsage
field: heapmemoryusage
- attr: NonHeapMemoryUsage
field: nonheapmemoryusage
- attr: ObjectPendingFinalizationCount
field: objectpendingfinalizationcount
- mbean: 'java.lang:name=*,type=MemoryPool'
attributes:
- attr: Usage
field: usage
- attr: PeakUsage
field: peakusage
- attr: CollectionUsage
field: collectionusage
- mbean: 'java.lang:name=*,type=GarbageCollector'
attributes:
- attr: CollectionTime
field: collectiontime
- attr: CollectionCount
field: collectioncount
- mbean: 'java.lang:name=*,type=GarbageCollector'
attributes:
- attr: LastGcInfo
field: lastgcinfo
- mbean: 'java.lang:type=Threading'
attributes:
- attr: TotalStartedThreadCount
field: totalstartedthreadcount
- attr: ThreadCount
field: threadcount
- attr: DaemonThreadCount
field: daemonthreadcount
- attr: PeakThreadCount
field: peakthreadcount
- mbean: 'java.lang:type=ClassLoading'
attributes:
- attr: LoadedClassCount
field: loadedclasscount
- attr: UnloadedClassCount
field: unloadedclasscount
- attr: TotalLoadedClassCount
field: totalloadedclasscount
3) ConfigMap을 통한 Metricbeat 설정 관리
- Helm Chart로 배포된 설정은 ConfigMap 형태로 관리가 됩니다.
- 배포 이후에 설정에 변경 시 ConfigMap 부분만 변경하면 어플리케이션의 재기동 없이도 적용이 됩니다.
- 아래는 elasticsearch 모듈 설정 내용입니다.
module : Metric 연동 모듈이름
metricsets: 수집된 MetricSets입니다. 하나의 모듈에 여러가지 Metricsets이 존재합니다.
period : 수집 주기
hosts : ElasticSearch 연동 정보
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
- module: elasticsearch
metricsets:
#- ccr
- cluster_stats
- index
- index_recovery
- index_summary
#- ml_job
- node
- node_stats
- pending_tasks
#- shard
period: 30s
hosts: ["http://localhost:9200"]
#username: "elastic"
#password: "changeme"
index_recovery.active_only: true
#xpack.enabled: false
4.4. ElastAlert을 사용한 관제 설정 추가
ElastAlert 관제 타입을 추가하였습니다.
| 관제 타입 | 관제설명 | 기존 | 신규 |
|---|---|---|---|
| Any | 매칭 Event 발생 | O | O |
| Frequency | 기간동안 매칭 Event 빈도 Flatline : Event 수의 임계치 미만 | O | O |
| Cardinality | 매칭되는 Event의 Unique Count의 임계값 초과/미만 | X | O |
| Percentage Match | 기간동안 매칭되는 Event의 발생 비율(%)의 임계값 초과/미만 | X | O |
| Spike | 기간동안 Event 개수의 급격한 증가/감소 Schedule : 해당 스케쥴 시간의 Event 발생이 없는 경우 | X | O |
| Change | Field의 Value 변경 | X | O |
| New_term | Field의 Value가 새로운 값 나타남 | X | O |
| Metric Aggregation | Field의 Value에 대한 min, max, avg, sum, cardinality, value_count의 임계값 초과/미만 | X | O |
| Spike | Filed Value Field의 Value에 대한 min, max, avg, sum, cardinality, value_count의 급격한 증가/감소 | X | O |
ElastAlert 구성
4.5. 모니터링 분석을 위한 다양한 종류의 Kibana Dashboard 구성
ElasticSearch로 수집된 로그데이터를 각각의 그래프, DataTable,Map 등으로 표현될 수 있고..이것을 하나의 Dashboard로 구성이 가능합니다.
4.5.1 로그 기반 대쉬보드 구성 예제
아래 그림은 사람인HR IT연구소의 푸쉬 전송 시스템의 로그를 기반으로
대쉬보드를 구성한 경우입니다.
메시지 푸쉬 타입별 카운트를 DataTable/Line Graphe등으로 표시하고
총 전송개수 및 발송에 대한 수치는 Metric으로 표현했습니다.
데이터 분석 시간은 분/시간/일/월 등으로 범위지정도 가능합니다.
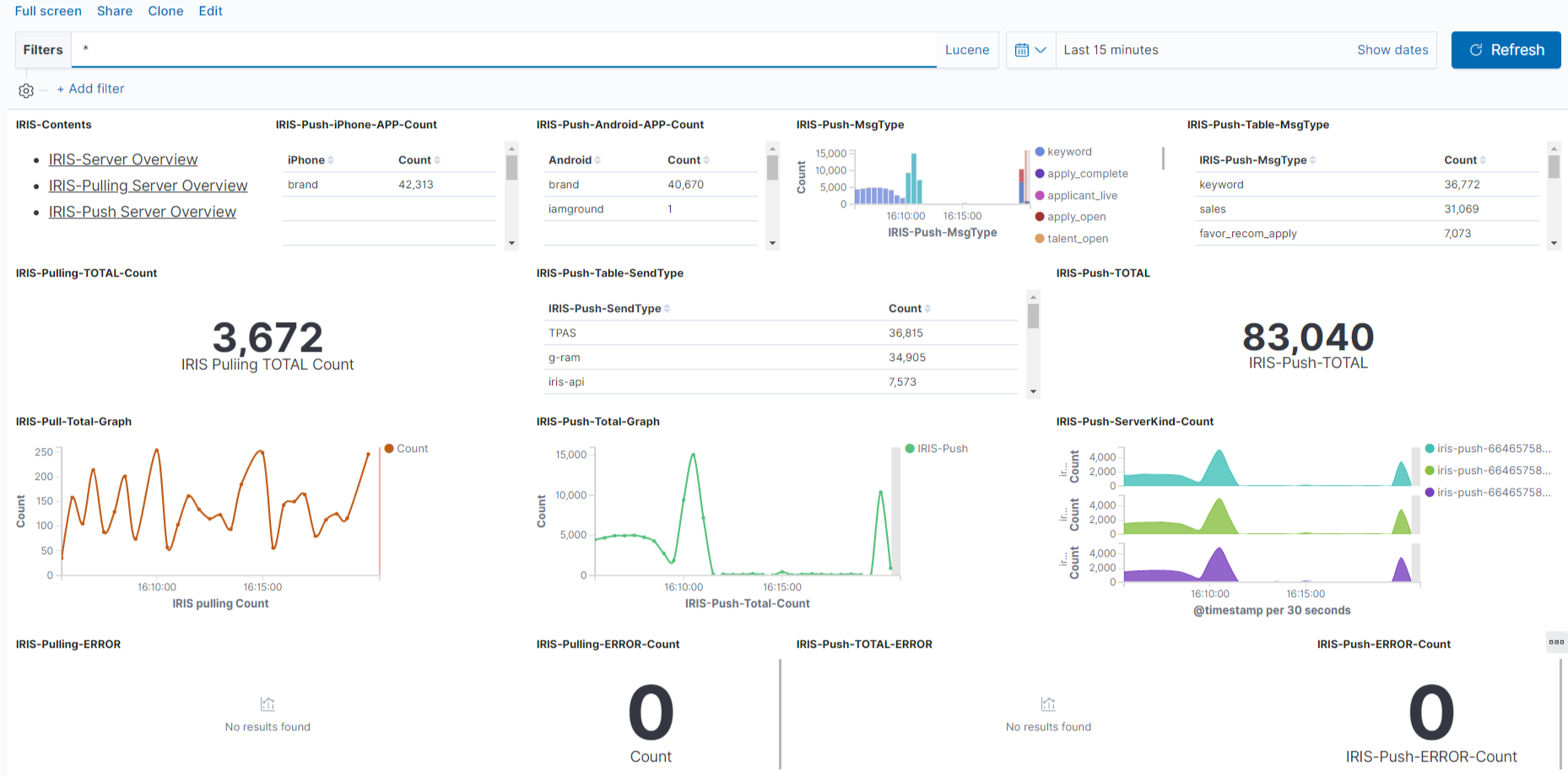
4.5.2 Metric 기반 대쉬보드 구성 예제
Metric 로그 수집이 추가되면서 Kibana에서 연동 시스템에 대한 정보도
대쉬보드를 추가하였습니다.
아래 그림은 Kafka에 대해서 수집된 Metric을 기반으로 Dashboard를 구성한 예제입니다.
연동 서비스에 대해서 Dashboard도 구성하여 문제 발생 시 어떤 서비스에 문제가 있는지
지연이 발생된 시간이나 수치를 분석함으로써 빠른 대응이 가능합니다.
5. 마무리
Heimdall 로그 관제 시스템에 대한 정리는 여기서 마칩니다.
로그에 대한 에러 및 분석에 대해서는 모든 개발자들이 고민하는 부분이고
각자만의 방식과 개발팀에 서비스에 따라 처리하는 방식들도 다양할 거 같습니다.
서비스인프라개발팀에서는 ELK 기반에서 로그에 대한 처리를 조금 더 쉽게 처리할 수 있게
고민하여 지금의 시스템을 구축하였습니다.
우선 쿠버네티스 기반 환경에서 어플리케이션 배포가 진행되면서 컨테이너 기반 환경에서도 가능한 관제시스템이 필요하였습니다. 그 결과로 Sidecar 형태로 로그 수집을 처리하는 구조가 개발이 되었고, 수집된 로그 정보는 각 서비스별로 Kibana에 Dashboard를 구성하여 개발자 및 운영자가 관리하기 쉽게 구성하였습니다. 서비스 연동에 대한 상태 정보는 Metric 정보를 수집하여 Kubernetes, Kafka, ElasticSearch 등 많은 연동 서비스에 대한 상태 정보를 확인하고 연동 시스템에 이상이 발생되는 경우 빠른 분석과 알림을 통지하여 빠른 장애 대응이 가능해졌습니다.
출처 및 참고 사이트
Kubernetes : https://kubernetes.io/ko/docs/concepts/overview/what-is-kubernetes/
Filebeat : https://www.elastic.co/kr/beats/filebeat
Metricbeat : https://www.elastic.co/kr/beats/metricbeat
Kafka : https://kafka.apache.org/intro
Logstash : https://www.elastic.co/kr/logstash
ElasticSearch : https://www.elastic.co/kr