MySQL Group Replication 구축
MySQL Group Replication 구축 사례
MySQL Group Replication 구축
소개
DA팀은 사람인의 모든 데이터를 담고있는 각각의 DBMS를 효과적이고 안정적으로 구축 및 운영하며 데이터의 품질을 높이고, 최적의 데이터 관리를 위해 전사적으로 데이터 표준을 구축하여 운영정책을 수립하고 관리하며 신규 시스템에 대한 기술검토를 수행 및 적용합니다. 상세하게는 데이터 모델링, DBMS 환경 구축, 데이터 이관, DBMS 성능개선, Troubleshooting등을 계획하고 수행합니다. 더 나아가 DA(데이터 아케틱처) 관점에서 조직의 목표를 달성하기 위한 시스템 구축 프로젝트 및 운영 환경의 Life Cycle에서 DBMS를 통한 데이터의 흐름을 설계하고 관리하고 있습니다.
도입 목적
먼저, DB 구성 중 가장 많은 고민과 시간을 투자하게 만드는 부분이 성능(Performance)과 고가용성(High Availabilty)이라고 생각합니다. 성능은 좋으면 좋을수록 좋겠지만, 서비스를 제공하는 입장에선 서버 장애로 서비스의 중단이 발생하지 않도록 안정성을 유지하는 것도 중요합니다. 이렇게만 이야기하면 Oracle의 RAC를 사용하는게 가장 좋은 선택이겠지만 비용대비 안정성을 확보 할 수 있으며, 성능도 좋은 DB를 구성해야함이 힘든 과제입니다. 저희 사람인은 RDBMS로 MySQL을 가장 많이 사용중에 있으며, Replication 구성에 MMM, MHA 등의 Third-Party 솔루션을 추가로 구성하여 서비스 성능과 안정성에 노력하고 있습니다. 아래는 도입을 검토함에 있어 DBMS 구성 시, 실제로 어떤 장점과 어떤 단점이 있는지에 대한 간단한 그림입니다.
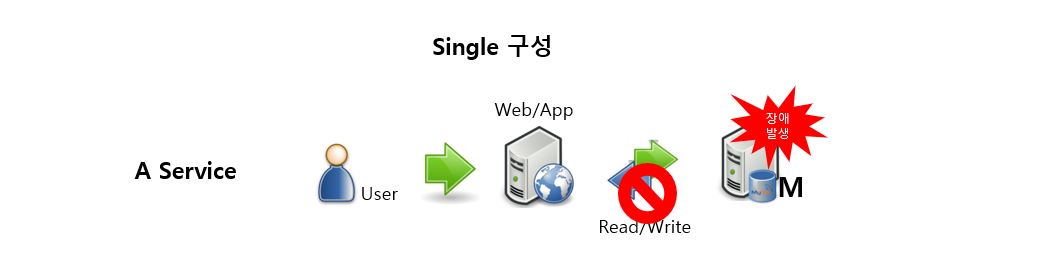
가장 단순한 MySQL Single 구성입니다. DB 장애가 곧 서비스 장애로 이어집니다.
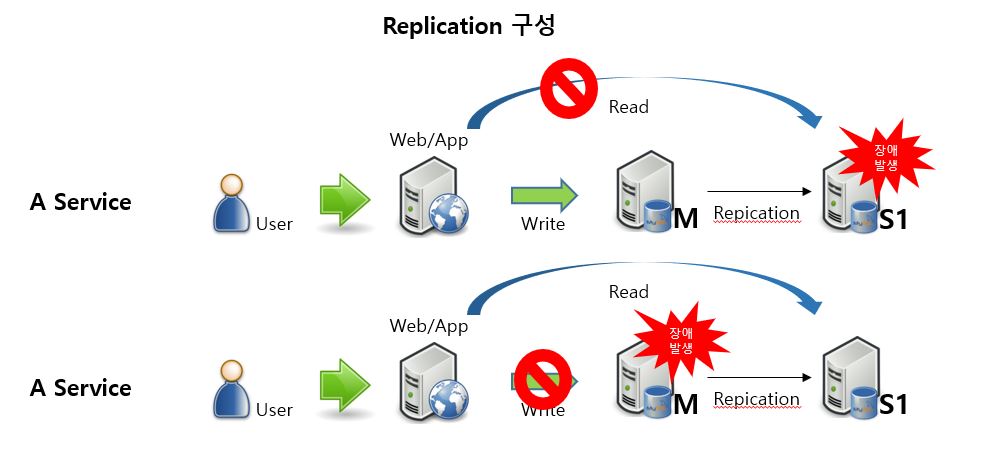
MySQL의 Replication을 사용하여 M - S1 구성입니다. Connection을 분리하여 사용중이라면, S1장애 발생 시, Read가 불가하며, 사용자가 수동으로 Web/App에서 Read Connection을 M으로 설정 할 때 까지의 시간은 Read 서비스 장애로 이어집니다. M 장애 발생 시, Write가 불가한 서비스 장애로 이어집니다. 사용자가 수동으로 S1을 M으로 승격하여 서비스는 지속 할 수 있으나, 장애 발생 시점부터 사용자가 수동으로 S1을 M으로 승격시키기고 Web/App에서 Connection을 변경 할 때 까지의 시간은 서비스 장애로 이어집니다.
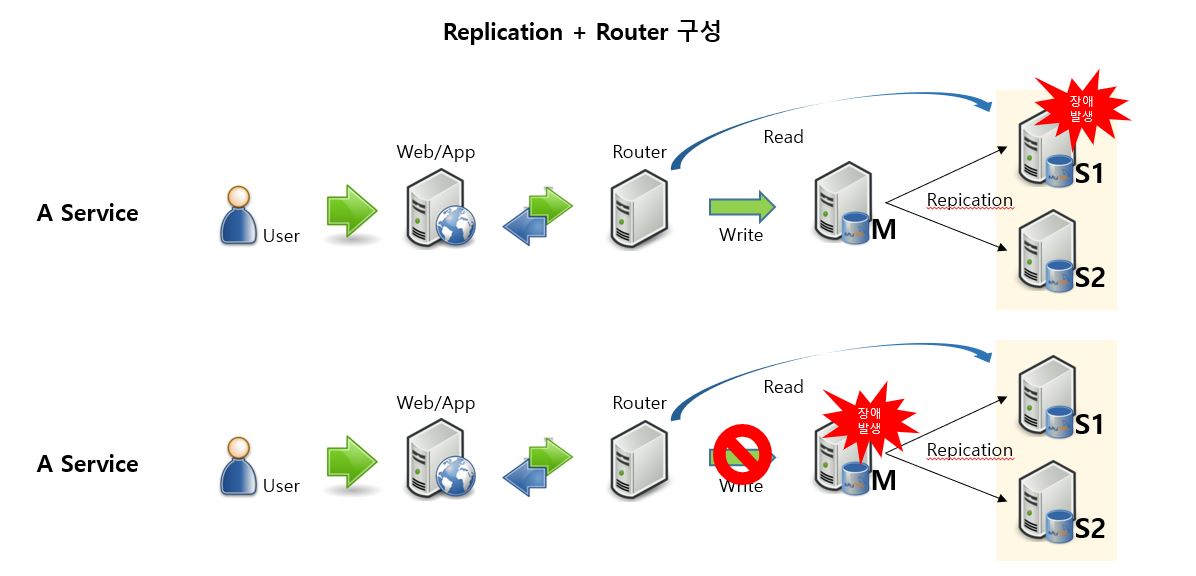
MySQL의 Replication을 사용하고 Web/App과 DB 사이에 Connection을 관리하는 Router를 추가한 M - S1/S2 구성입니다. Read 성능을 높이기 위해 많이 사용하는 구성입니다. S1 장애 발생 시, 이미 설정 된 Router 설정 정보에 따라 S2에서 서비스를 지속 할 수 있으며, 사용자의 직접 개입이 없습니다. M 장애 발생 시, Write가 불가한 서비스 장애로 이어집니다. 사용자가 수동으로 S1을 M으로 승격하고 S2를 새로운 M과 Replication을 설정하여 서비스는 지속 할 수 있으나, 장애 발생 시점부터 사용자가 수동으로 S1을 M으로 승격시키고 S2를 새로운 M과 Replication을 설정 할 때 까지의 시간은 서비스 장애로 이어집니다.
승격에 대한 내용은 단순하게 표현한 것이며, 실제로는 어느 Slave가 Master로 승격 될지 구분하여야 하며, 모든 Slave가 동일하게 Binary Log 이벤트를 수신하지 않았을 가능성도 있습니다. 이러한 일관성 문제를 방지하려면 매우 복잡하고 수동으로 수행하기 어려울 수 있습니다.
여기까지 구성했다면 Read(읽기), 즉 Slave에 대한 장애 발생은 사용자의 개입없이 서비스 장애로 이어지지 않게 구성이 가능합니다. 이제 Write(쓰기), 즉 Master에 대해서도 장애 발생 시 사용자의 개입없이 서비스 장애로 이어지지않게끔 구성하는 방법이 필요합니다.
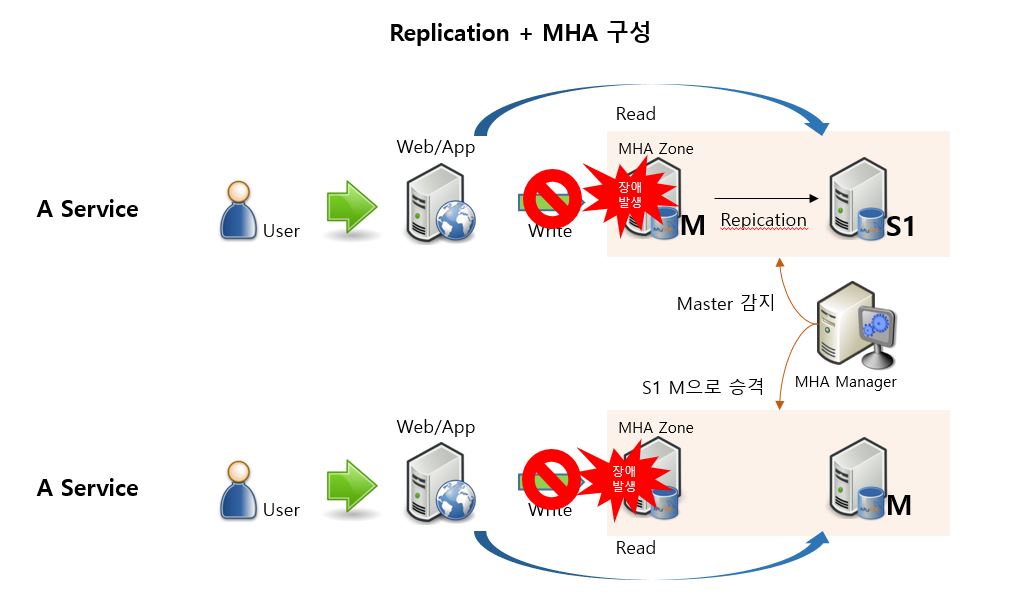
MySQL의 Replication을 사용하고 Failover를 관리 할 수 있는 MHA를 사용한 구성입니다. MHA Manager 에서 계속적으로 Health Check를 진행하다 M 장애 발생 시, Write가 일시적으로 불가한 서비스 장애로 이어집니다. 그리고 이미 설정 된 MHA 설정 정보에 따라 S1을 M으로 Auto Failover하여 자동으로 승격합니다. Read는 계속적으로 서비스가 이어지나, Web/App에서 Write Connection을 새로운 M으로 설정 할 때 까지의 시간은 서비스 장애로 이어집니다.
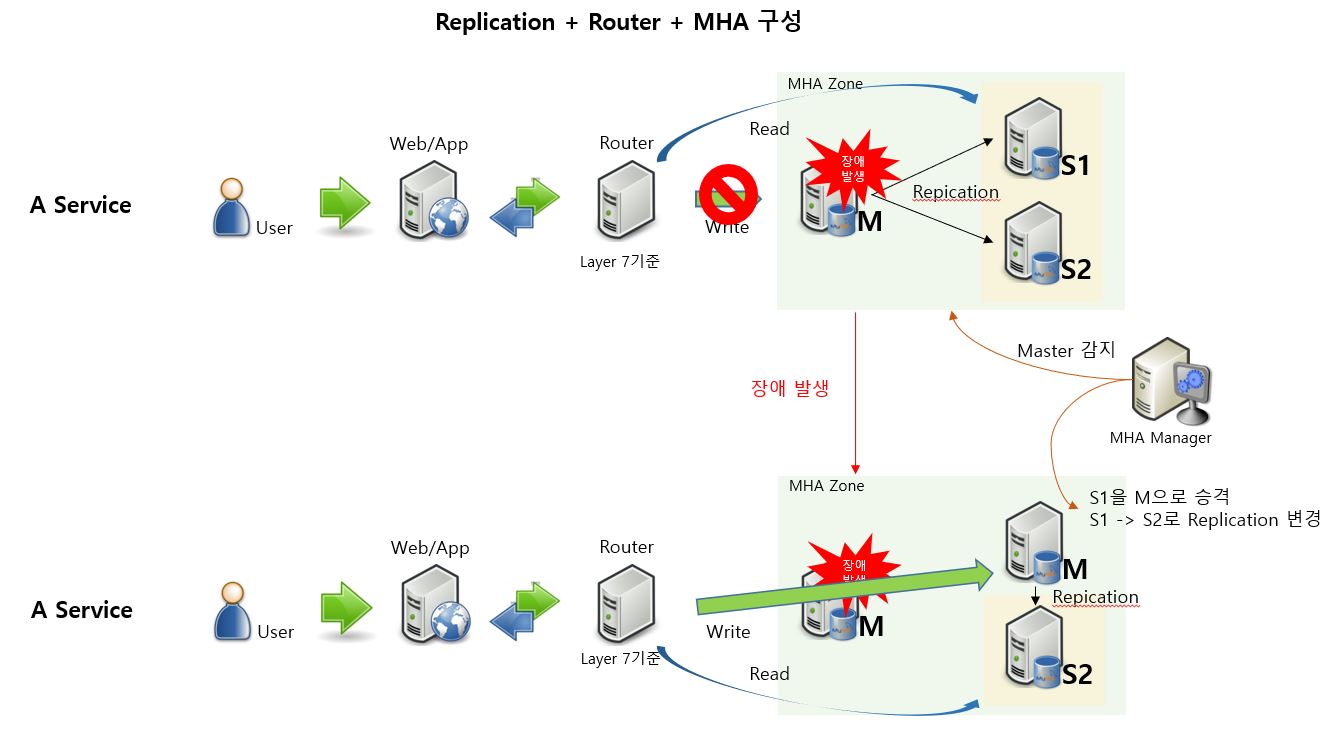
MySQL의 Replication을 사용하고 Web/App과 DB 사이에 Connection을 관리하는 Router를 추가 후, Failover를 관리 할 수 있는 MHA를 사용한 구성입니다. M 장애 발생 시, 이미 설정 된 MHA 설정 정보에 따라 S1을 M으로 Auto Failover하여 자동으로 승격합니다. Read는 계속적으로 서비스가 이어지나, Write는 승격하는 시간동안 일시적인 서비스 장애가 발생합니다. 승격에 소요되는 시간은 대략 10초 ~ 30초정도 소요됩니다. 이 구성은 사용자의 개입없이 서비스가 복구되어 지속 될 수 있습니다. (참고로 Router 에서 사용되는 Load Balancer에서 Layer 4를 사용하는 것과 Layer 7을 사용하는 것에도 구성의 차이가 있으며, 아래에 설명 예정)
저희 DA팀은 MHA를 잘 활용중에 있지만, MHA를 만든 Yoshinori가 Facebook에 입사하며, v0.58을 끝으로 최신 버전을 지원할 수 있는 MHA는 출시되지 않고 있습니다. 그래서 8.0.19에서 나온 zstd 압축 알고리즘 사용문제, 명령어 변경등으로 사용자가 직접 deb 패키지를 풀어 소스 변경 후 재컴파일하는 등의 작업이 필요할 수 있습니다.
그래서 이러한 번거로움과 문제가 발생 할 수 있음을 미연에 방지하기 위해 Third-Party 솔루션이 아닌 Bendor사에서 제공해주는 Group Replication을 테스트 및 구축하여 서비스를 진행하기로 합니다.
구현
사실 MySQL의 Group Replication은 Oracle의 RAC처럼 복잡한 구현이 필요하지도 않으며, SAN(Storage Area Network)처럼 값비싼 기반 장비를 구매해야 하는 것도 아닙니다. 간단하게 표현하면 Binary Log를 Replica에 적용 및 반영하는 부분이 변경되었습니다.

출처 : https://dev.mysql.com/doc/refman/8.0/en/group-replication-summary.html
근데 위와 같이 Group Replication의 Binary Log를 적용하는 부분을 보면 MySQL의 고가용성에 충분히 고민해보셨던 분이라면 특정 Third Party 솔루션이 생각나실 수 있을 것 같습니다. 과거에 Galera-cluster를 서비스에 적용하기위해 테스트를 진행하였는데, 각 노드 간 데이터 복제를 요청하고, 그 노드에서 복제 요청 대기, 쓰기 속도 저하 및 Multi Master 사용으로 Deadlock 이슈 등으로 테스트만 진행 후 서비스에 적용하진 못 했었습니다. 그럼 MySQL의 Group Replication은 그런 단점에서 벗어날 수 있었을까요 ? 제가 테스트 했을 시, Galera-cluster에서 존재했던 모든 단점은 MySQL Group Replication에서도 비슷하게 발생했습니다. 그러나 MySQL에서 만들었기에 운영 및 관리가 용이하다는 점, 성능의 최대치의 부하 시 예상보다 많이 저하되지는 않는 점 등과 특히 HA동작이 안정적으로 동작함을 고려하여 도입을 진행하게 되었습니다.
우선 Sysbench를 사용하여 동일한 노드에서 MySQL의 Replication과 Group Replication의 최대 부하 테스트를 진행합니다. 테스트 시점마다 수치가 조금씩 차이날 수 있으니 추세만 보시면 됩니다. 단순 CRUD 형태이지만 의미있는 결론을 얻을 수 있었습니다. Binary Log를 적용하는 방법이 바뀐 Group Replication의 최대 부하는 일반적인 Replication보다 약 10 ~ 40%까지도 쓰기 성능 하락이 발생합니다. 또한 Galera-cluster에서 발생되었던 Lock으로 인한 이슈 역시 비슷하게 발생되었습니다. 최대치에 대한 부하 테스트이기 때문에 일반 Replication 대비 무조건적으로 성능은 떨어진다고는 할 수 없습니다.

이에 만약 Group Replication을 검토중이라면, 성능상의 이슈로 사용자의 유입이 많은 CRUD가 많은 메인 서비스에 적용하기보단, 서비스의 안정성이 최우선시 되어야하며, 대국민서비스가 아니라 TPC 수치상 CRUD가 안정적으로 유지되는 서비스에 적용하기로 했습니다. 그래서 Multi Master보다는 고가용성에만 초점을 맞추어 Single Primary로 적용하여 장애 발생 시, HA가 정상적으로 동작되도록 구성하기로 합니다.
참고로 Multi Master 사용 시, Auto Increment의 값이 중복됨을 방지하기 위해 서버 수만큼 증가하는 설정을 해야됩니다. Galera-cluster와 동일합니다.
Group Replication 구성 방법
- 필수 설정
1
2
3
4
root # vi /etc/hosts
192.168.0.100 group-repl-db-1
192.168.0.101 group-repl-db-2
192.168.0.102 group-repl-db-3
-> /etc/hosts에 Group Replication에 구성 될 모든 서버가 지정되어 있어야 합니다.
1
2
3
4
5
6
disabled_storage_engines="MyISAM,BLACKHOLE,FEDERATED,ARCHIVE,MEMORY"
gtid_mode=ON
log_slave_updates=ON
binlog_format=ROW
master_info_repository=TABLE
relay_log_info_repository=TABLE
-> Storage Engine은 Innodb를 사용해야하며, GTID, Repository는 TABLE, Binary Log Format은 ROW, 보통은 Chain Replication에 사용하는 log_slave_updates 도 ON으로 설정되어 있어야 합니다. 그 외 모든 테이블엔 Primary key가 존재해야 합니다. Group Replication에서도 필요하지만, Binary Log가 ROW Foarmat일 경우, 모든 SQL이 PK가 있어야 빠르게 적용됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
####################################################
# Group Replication Plugin Install
####################################################
plugin_load_add='group_replication.so'
####################################################
# 서버 시작 후 바로 Group Replication 시작 할지 여/부
####################################################
group_replication_start_on_boot=off
####################################################
# 초기 Group Replication 설정 시 필요. 재구축시 Master 1대에서만 진행
####################################################
group_replication_bootstrap_group=off
####################################################
# Multi Master = X. Single Primary = O
####################################################
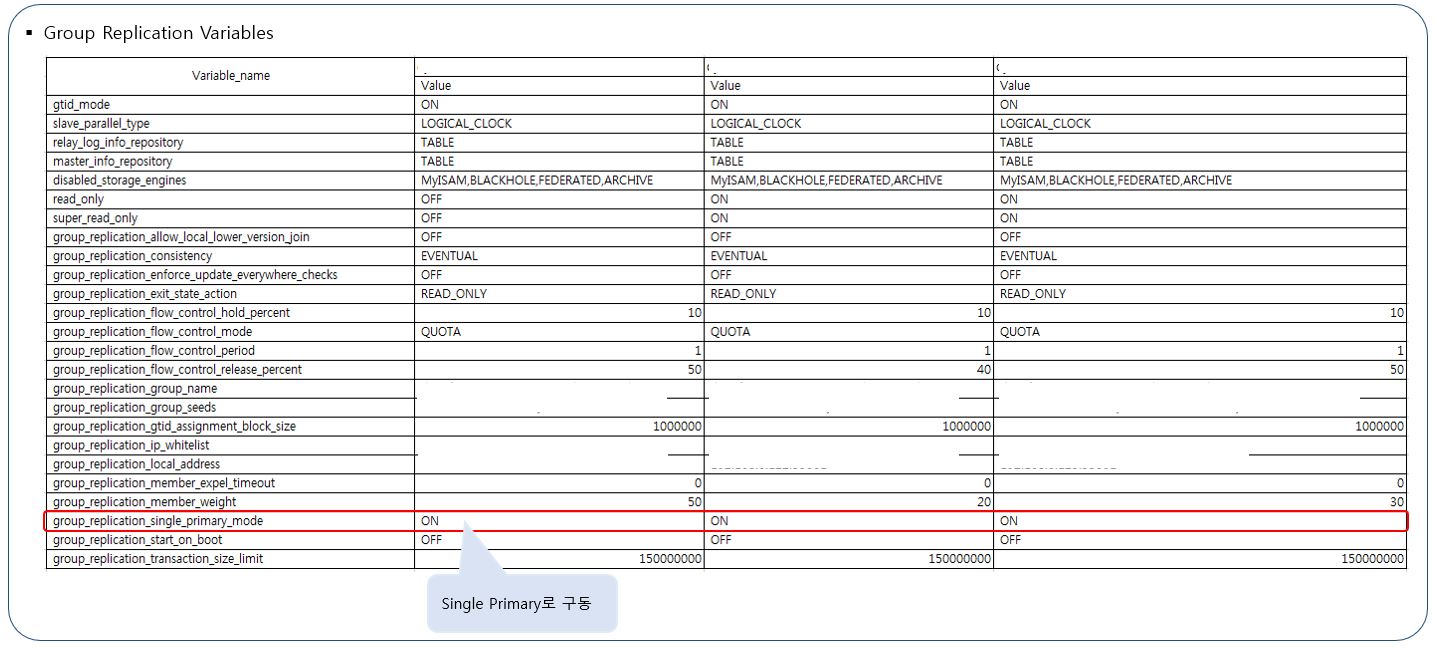
group_replication_single_primary_mode=ON
####################################################
# Group Replication Config
####################################################
group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa"
group_replication_local_address= "group-repl-db-1:33061"
group_replication_group_seeds= "group-repl-db-1:33061,group-repl-db-2:33061,group-repl-db-3:33061"
-> Group Replication에서 사용하는 필수 설정은 위와 같습니다. DB 기본 PORT인 3306 외에 33061 포트가 오픈되며, Group Replication의 내부적인 통신을 위해 사용됩니다. 오라클 RAC의 Private IP처럼 서비스 외, 내부적인 통신을 위해 사용되는 PORT로 판단됩니다.
1
2
3
4
5
mysql ((none))>INSTALL PLUGIN group_replication SONAME 'group_replication.so';
Query OK, 0 rows affected (0.10 sec)
mysql ((none))>INSTALL PLUGIN clone SONAME 'mysql_clone.so';
Query OK, 0 rows affected (0.10 sec)
-> 그 외 Group Replication에서 사용되는 플러그인을 직접 설치합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
##########################
# GROUP_REPLICATION M NODE
##########################
mysql ((none))>CHANGE MASTER TO
-> MASTER_USER='xxxxxxxx',
-> MASTER_PASSWORD='xxxxxxxx'
-> FOR CHANNEL 'group_replication_recovery';
Query OK, 0 rows affected, 2 warnings (0.05 sec)
################################################################################
# 그룹을 처음 시작하는 과정에서 group_replication_bootstrap_group 설정이 필요하며, 1회만 수행해야 합니다.
# Single Priamry 및 Group을 시작하는 서버에서 최초 1회만 수행(config 파일에는 OFF로 되어있음)
################################################################################
mysql ((none))>SET GLOBAL group_replication_bootstrap_group=ON;
Query OK, 0 rows affected (0.00 sec)
mysql ((none))>START GROUP_REPLICATION;
Query OK, 0 rows affected (3.07 sec)
mysql ((none))>SET GLOBAL group_replication_bootstrap_group=OFF;
Query OK, 0 rows affected (0.00 sec)
mysql ((none))>SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+----------------+-------------+--------------+-------------+----------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION |
+---------------------------+--------------------------------------+----------------+-------------+--------------+-------------+----------------+
| group_replication_applier | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx | group-repl-db-1| 3306 | ONLINE | PRIMARY | 8.0.20 |
+---------------------------+--------------------------------------+----------------+-------------+--------------+-------------+----------------+
1 row in set (0.00 sec)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
##############################
# GROUP_REPLICATION S1/S2 NODE
##############################
mysql ((none))>CHANGE MASTER TO
-> MASTER_USER='xxxxxxxx',
-> MASTER_PASSWORD='xxxxxxxx'
-> FOR CHANNEL 'group_replication_recovery';
Query OK, 0 rows affected, 2 warnings (0.05 sec)
################################################################################
# group_replication_bootstrap_group은 1번 노드에서 수행하였기 때문에
# 위 CHANGE MASTER 후 START GROUP_REPLICATION;
################################################################################
mysql ((none))>START GROUP_REPLICATION;
Query OK, 0 rows affected (3.07 sec)
mysql ((none))>SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+----------------+-------------+--------------+-------------+----------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION |
+---------------------------+--------------------------------------+----------------+-------------+--------------+-------------+----------------+
| group_replication_applier | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx | group-repl-db-1| 3306 | ONLINE | PRIMARY | 8.0.20 |
| group_replication_applier | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx | group-repl-db-2| 3306 | RECOVERING | SECONDARY | 8.0.20 |
+---------------------------+--------------------------------------+----------------+-------------+--------------+-------------+----------------+
2 rows in set (0.00 sec)
mysql ((none))>SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+----------------+-------------+--------------+-------------+----------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION |
+---------------------------+--------------------------------------+----------------+-------------+--------------+-------------+----------------+
| group_replication_applier | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx | group-repl-db-1| 3306 | ONLINE | PRIMARY | 8.0.20 |
| group_replication_applier | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx | group-repl-db-2| 3306 | ONLINE | SECONDARY | 8.0.20 |
| group_replication_applier | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx | group-repl-db-3| 3306 | RECOVERING | SECONDARY | 8.0.20 |
+---------------------------+--------------------------------------+----------------+-------------+--------------+-------------+----------------+
2 rows in set (0.00 sec)
mysql ((none))>SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+----------------+-------------+--------------+-------------+----------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION |
+---------------------------+--------------------------------------+----------------+-------------+--------------+-------------+----------------+
| group_replication_applier | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx | group-repl-db-1| 3306 | ONLINE | PRIMARY | 8.0.20 |
| group_replication_applier | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx | group-repl-db-2| 3306 | ONLINE | SECONDARY | 8.0.20 |
| group_replication_applier | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx | group-repl-db-3| 3306 | ONLINE | SECONDARY | 8.0.20 |
+---------------------------+--------------------------------------+----------------+-------------+--------------+-------------+----------------+
2 rows in set (0.00 sec)
-> 여기까지 진행되면 Group Replication의 기본 설치 및 구성이 완료됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# PRIMARY / SECONDARY 형식으로 장애 시 HA가 동작됩니다.
# 초기 세팅 후 Failover 동작 시 다음 PRIMARY로 승격되는 설정을 확인 시,
mysql ((none))>show global variables like '%group_replication_member_weight%';
+---------------------------------+-------+
| Variable_name | Value |
+---------------------------------+-------+
| group_replication_member_weight | 50 |
+---------------------------------+-------+
1 row in set (0.01 sec)
# Default 값인 50으로 설정되어 있음을 확인 할 수 있습니다.
# 각 DB별 아래와 같이 설정 시, PRIMARY 장애 시, SECONDARY 중, group_replication_member_weight가 높은 group-repl-db-3 가 PRIMARY가 됩니다.
# group-repl-db-1
set global group_replication_member_weight = 50;
# group-repl-db-2
set global group_replication_member_weight = 10;
# group-repl-db-3
set global group_replication_member_weight = 40;
# 그 외 PRIMARY를 수동으로 변경(Failback)이 필요할 시, group_replication_set_as_primary로 변경합니다.
mysql ((none))>SELECT group_replication_set_as_primary('xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx');
# 예시는 MEMBER_ID가 다 동일하지만, Unique한 값입니다.
-> 간단한 HA 설정 및 동작 테스트입니다.
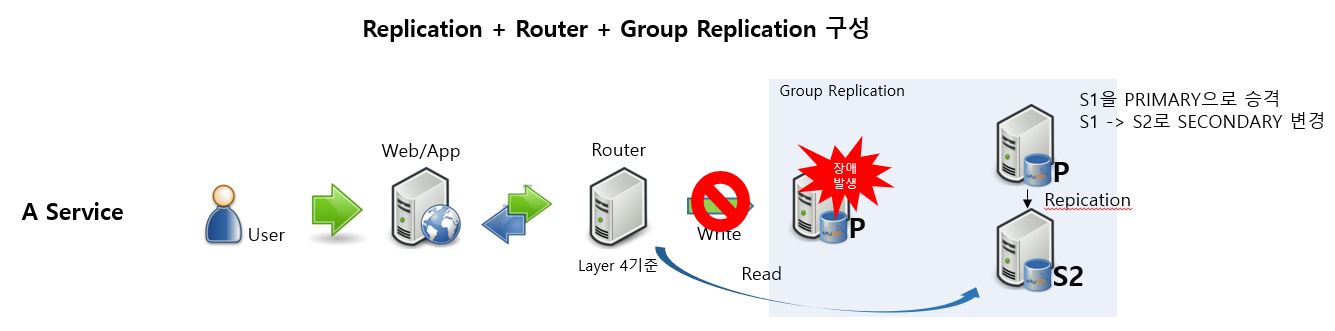
-> Layer 4 기준으로 Group Replication 구성 시, Router에서는 Auto Failover에 따른 Write가 변경되고 Read가 변경되는 유연한 설정을 따라 갈 수 없습니다.
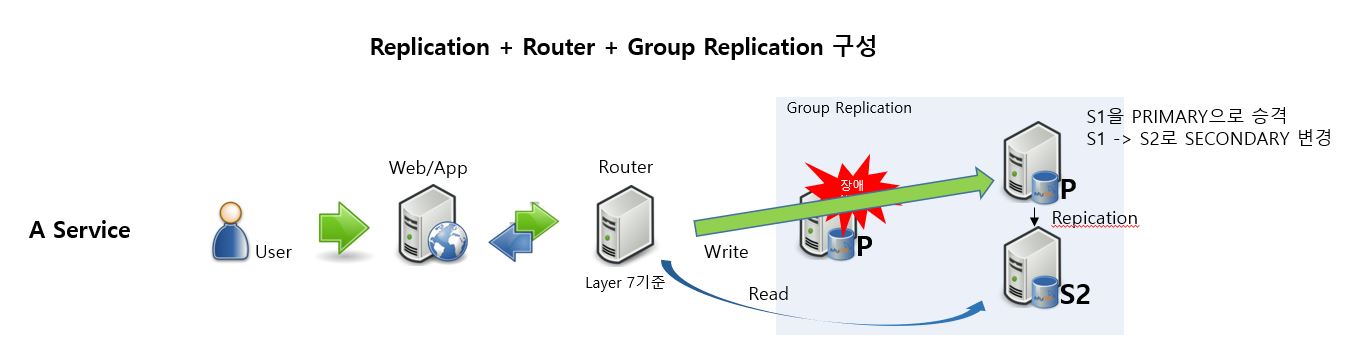
-> 이에 Router는 Auto Failover에 Write 및 Read 가 유연하게 변경 될 수 있도록 Layer 7 기준으로 Group Replication 구성 할 때 고려되어야 합니다. 하지만 Layer 7의 기능을 가진 HAProxy로 MySQL의 Group Replication 구성 시, DB 서버 모니터링 시 Web/App의 Source(Client) IP Address를 노출하지 않고, Router IP Address를 노출합니다. 그래서 HA(고가용성) 기능을 전부 활용하면서 Web/App의 Source(Client) IP Address를 확인하여 DB모니터링도 빠짐없이 진행하려면 MySQL 계열의 DBMS 중 Proxy Protocol을 지원하는 Percona For MySQL 이나 MariaDB를 사용하여야 합니다.
2021년 09월 기준으로 MySQL 모든 버전은 Proxy Protocol을 지원하지 않습니다.
Percona For MySQL에서 설정은 proxy_protocol_networks=’192.168.xx.xx1,192.168.xx.xx2,192.168..xx.xx3’ 와 같이 Router IP를 설정합니다.
이제 HAProxy에서 Group Replication의 장애 발생 시 PRIMARY와 SECONDARY를 구분하고 모니터링 할 수 있는 스크립트를 작성합니다.

-> Group Replication의 모든 서버에 HAProxy에서 HTTP 요청이오면 현재 DB서버의 상태를 알려주는 SCRIPT 작성를 작성하여 데몬으로 올려놓았습니다.
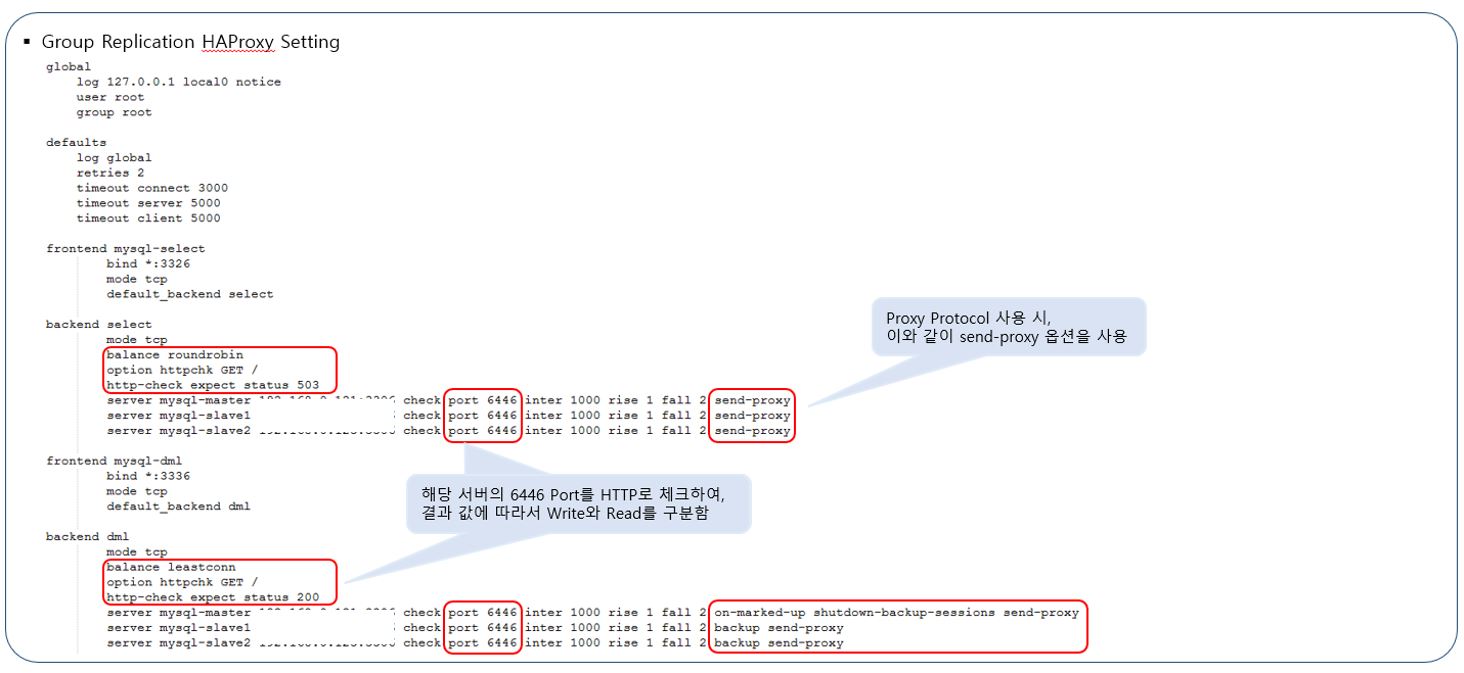
-> HAProxy에서 설정입니다. Health Check & HAProxy 스크립트는 링크를 참고했습니다.
https://mysqlhighavailability.com/mysql-group-replication-a-quick-start-guide/
HA 동작시 HAProxy를 통하여 어플리케이션이 마스터와 슬레이브를 찾아 갈 수 있도록 적용하였습니다.
예제는 간단하게 작성해본 스크립트이며 실제 구성 및 상황에 맞게 재작성하시면 됩니다.
그 외, Group Replication의 요구 사항이나, 제한 사항은 공식 매뉴얼을 참고하시면 됩니다.
https://dev.mysql.com/doc/refman/8.0/en/group-replication-requirements.html
https://dev.mysql.com/doc/refman/8.0/en/group-replication-limitations.html
Group Replication 테스트
Group Replication Member ADD
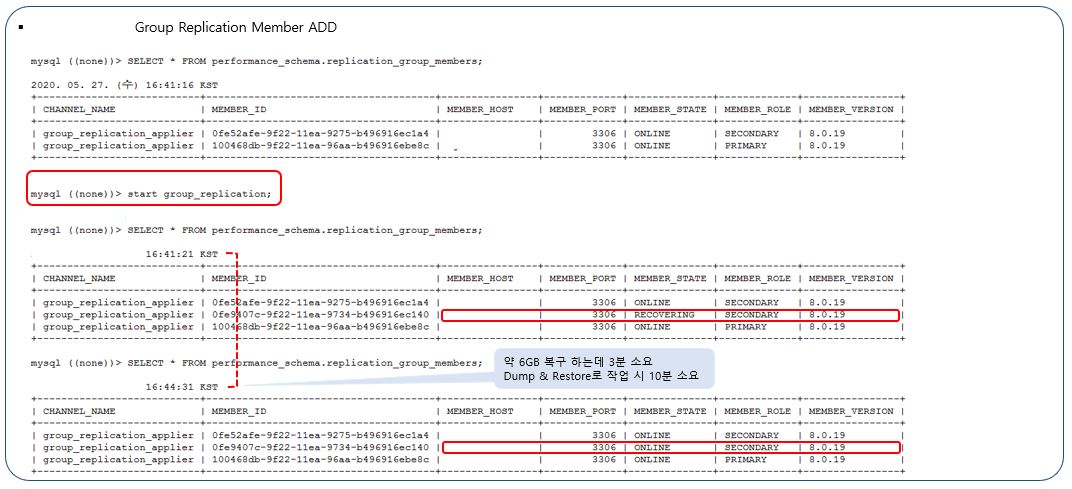
-> 데이터 파일 사이즈 약 6GB로, 일반적인 Dump & Restore 시 소요시간은 10분이 소요되었으며, Group Replication Member ADD 시 1/3 정도로 시간이 줄어든 3분정도 소요됨을 확인 할 수 있습니다.
Stop Group_Replication; MySQL Stop 등
-> 위에 한 차례 설명해놓은대로 group_replication_member_weight가 높은 순으로 다음 Primary가 정해짐. 강제 Role Change의 경우만 지정한 MEMBER_ID의 값으로 변경 됨.
Sysbench Read 중 장애(HAProxy)
-> Group Replication 중단 시(stop group_replication;) MEMBER_STATE가 OFFLINE이어도 이미 접속 된 Thread는 수행중인 Read를 계속적으로 수행. MySQL 중단 시(service mysql.server stop) 중단 된 서버의 Thread는 Reconnect 되며 중단되지 않은 DB 서버로 Connect하여 Read를 계속적으로 수행.
Sysbench Write 중 장애
-> Read와 다르게, 모든 Thread는 Reconnect 되며 신규 PRIMARY로 접속 됨.(Group Replication 중단 및 MySQL 중단 둘 다 동일함). 추가로 강제로 MySQL의 프로세스를 강제로 Kill 하고 다시 Group Replication의 멤버로 포함해도 모든 데이터는 동일함을 테스트함.
문제
큰 트랙잭션일 경우 아래와 같은 에러가 발생함.
약 50 ~ 100만건 정도의 INSERT ~ SELECT 시 발생한 에러 메세지.
ERROR 3100 (HY000): Error on observer while running replication hook ‘before_commit’.
https://support.oracle.com/epmos/faces/DocumentDisplay?_afrLoop=70973376174797&parent=EXTERNAL_SEARCH&sourceId=HOWTO&id=2456364.1&_afrWindowMode=0&_adf.ctrl-state=mfxzxt006_4
이는 Group Replication 구성 시, 큰 트랜잭션으로 인한 문제를 피하기 위해, 트랜잭션 크기에 제한을 둔 설정이므로, group_replication_transaction_size_limit, group_replication_member_expel_timeout 등등으로 회피 할 수 있으나, 큰 트랜잭션으로 인한 문제가 발생 할 수 있으므로, 작은 단위의 트랜잭션으로 잘라서 수행함이 필요합니다.
네트워크 트래픽이 높을 경우, Group Replication 내부 통신에서 일시적인 단절이 발생 시 Group Replication 멤버와 문제가 발생한 것으로 판단하여, Group에서 제외 되는 현상.
특별한 에러 메세지는 없으나, Warning으로 ‘Member with address group-repl-db-1:3306 has become unreachable’ 등과 같은 메세지가 발생합니다.이에 멤버를 그룹에서 추방하거나, HA가 동작하는 일이 발생 할 수 있습니다. Layer 7으로 구성 시, HA가 동작하여 Read 및 Write가 바로 서비스로 이어지나, 해결이 필요 할 시, 내부 헬스체크에 너무 민감하게 반응하지 않도록 설정하는 방법이 필요합니다.
group_replication_force_members
group_replication_exit_state_action
group_replication_unreachable_majority_timeout
group_replication_autorejoin_tries(8.0.20 이전엔 0, 8.0.20 이후엔 3이 Default)
참고로 Oracle RAC 설정을 기준으로 Private 네트워크를 Public 네트워크와 분리하여 사용하는 것도 방법일 수 있다고 생각합니다.
계속 업데이트 예정이지만 현재로선 위 두 가지에 대해서만 문제가 발생하였습니다.
후기
해당 서비스는 2020년 하반기에 오픈하여 현재까지 이슈없이 안정적으로 서비스되고 있습니다. 국내 레퍼런스가 많지않아 운영 후 계속적으로 모니터링 및 헬스체크를 위한 내부 스크립트를 보완하고 있습니다. 향후 Multi Master를 안정적으로 지원 할 수 있게되고, Write 성능이 일반 Replication 대비 8 ~ 90%정도로 올라올 수 있다면 더 큰 서비스의 DB로 대체도 가능하지 않을까 싶습니다.. 현재로선 Group Replication의 구성에 노드의 제한도 있고, 위와 같이 트랜잭션 크기등도 제한이 있어서 메인 서비스 외 일부 서비스에만 사용되고 있습니다.
구성 및 오픈시점부터 지금까지 문제를 해결 할 수 있도록 도와주고 작업을 지원해주신 DA팀, SE팀 및 IT전략팀 팀원 분들께 감사드립니다.