사이트 신뢰성에 대한 지표는 어떻게 구성할까? (Feat. SRE)
통상 많은 기업들이 시스템의 전반적인 지표는 수집하여 관리와 모니터링 그리고 알림을 받거나 하고 있을거예요. 하지만 서비스 레벨에 대한 지표에 대해서는 부족한 면이 많을겁니다. 사람인도 그렇듯 사이트 신뢰성을 위한 서비스 레벨의 지표와 목표 범위를 지정하기 위해 시작하게 되었습니다. 이런 지표를 만들고 보면 단기간이든 장기간이든 전체 Request들에 대해 서비스 개선이 좀 있었나 미비했나를 알 수 있지 않을까요?
그럼 이번에 진행 했던 내용을 공유 드릴게요.
용어 정리
들어가기에 앞서 간단하게 용어 2가지 정도 알아보고 가볼게요.
SLI(Service Level Indicator) - 서비스 수준 지표
서비스 수준을 판단 할 수 있는 요소를 측정한 것 입니다.
예를 들어 응답속도, 에러율, 처리량, 가용성, 내구성 등이 포함 될 수 있겠네요.
SLO(Service Level Object) - 서비스 수준 목표
SLI에 의해 측정된 서비스 수준의 목표로 하는 값 입니다.
예를 들어 최대 부하시 응답시간이 200ms를 초과하지 않아야 한다 라는 목표가 됩니다.
용어에서 나오는 내용 토대로 SLI, SLO에 대해서 수집 해보겠습니다.
구성
사람인은 관련 지표에 대한 수집으로 웹서버 로그를 이용하였습니다.
웹서버의 로그포맷 4가지를 이용 했어요.

$status : 정상적인 호출인지 실패된 호출인지 알기 위한 상태 코드
$host : referrer가 아닌 실제 접근한 도메인을 알도록
$upstream_response_time : 백엔드에서 실행하여 응답을 준 시간
$request : 사용자가 어떤 URI를 통해 접속 했는지 확인
이제 웹서버에 추가한 로그 포맷에 대한 값이 쌓이게 됩니다.
그 로그를 Elastic에 적재해서 시각화 해보려고 합니다.
먼저 각 Request에 대해 페이지 네임을 매핑 시키려고 합니다. 직접 담당하는 개발자가 아니라면 Request만 보고서는 어떤 페이지인지 식별하기 어렵기 때문입니다. 구현하려고 하는 Dashboard는 여러 팀에서 참고가 될 수도 있기 때문에 좀 더 명확한 구분이 되어야 할 것 같습니다.
실제 Request와 웹페이지를 매핑 시키면 아래와 같은 표가 되겠네요.
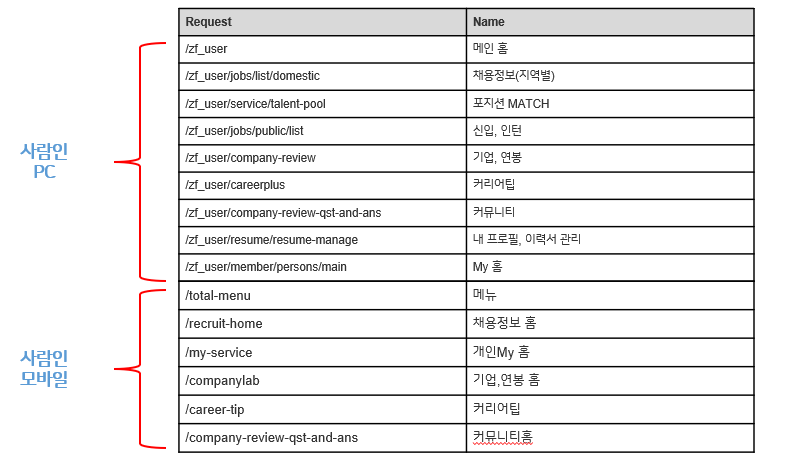
(일부 Request 만 표시 함)
해당 매핑 작업은 Scripted Fields를 사용하여 데이터 전처리를 진행 했어요. 언제든지 Request나 페이지 이름이 바뀐다면 Index에 영향을 안주는 선에서 바꿀 수 있도록 하기 위해서 입니다.
수집한 로그에 대한 Dashboard는 내부 요구사항이 있어 모여진 각 Dashboard 마다 Date Aggregation이 진행 될 수 있어야 하기에 Kibana의 Canvas 사용하여 여러 Dashboard를 한 곳에서 볼 수 도록 하였습니다. Canvas에서도 각 Dashboard를 모아놓고 볼 수 있는데, 각 Dashboard에 대해 개별로 기간을 두고 조회해 볼 수 있습니다.
Kibana Canvas는 데이터 시각화 및 프레젠테이션 도구로, Elasticsearch에서 라이브 데이터를 가져온 다음 데이터를 색상, 이미지, 텍스트 및 상상력과 결합하여 여러 페이지에 걸쳐 픽셀 하나하나까지 완벽한 동적 디스플레이를 만들 수 있습니다. 조금은 창의적이고, 조금은 기술적이며, 호기심이 많은 분이라면 Canvas가 적합합니다.
그럼 이제 데이터를 Elastic으로 수집을 했고, 해당 데이터만 가지고도 10개 이상의 Dashboard를 만들 수 있었어요. 간략하게 어떤 Dashboard를 만들었는지 훑어보겠습니다.
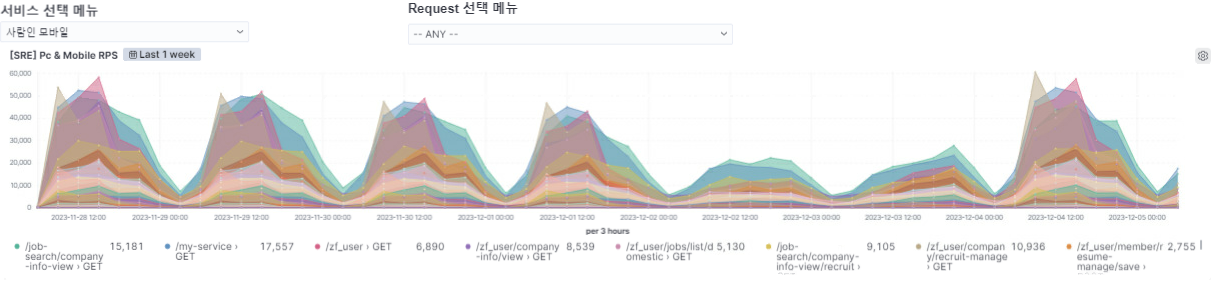
서비스 선택 메뉴에서 서비스를 선택하고 원하는 Request에 대해서만 전체 대시보드에 조회 합니다. ANY/ANY로 하면 전체 서비스의 전체 리퀘스트에 대한 값이 모든 Dashboard에 반영 됩니다.
위 대시보드는 RPS로 초당 Request를 확인하는 그래프 입니다.
각 Request별로 GET 호출이나 POST 호출 등 진행 내용을 그래프로 볼 수 있습니다.

SLI를 응답시간으로 하고 SLO를 2초로 기준 삼고 2초 미만에 대해 평균 응답율을 측정 하였습니다.
여기서 추가로 전월 대비 증감도 표시 하도록 했고, 2초 이상 발생한 건수는 몇 건이나 되는지에 대해서도 추가 하였습니다.
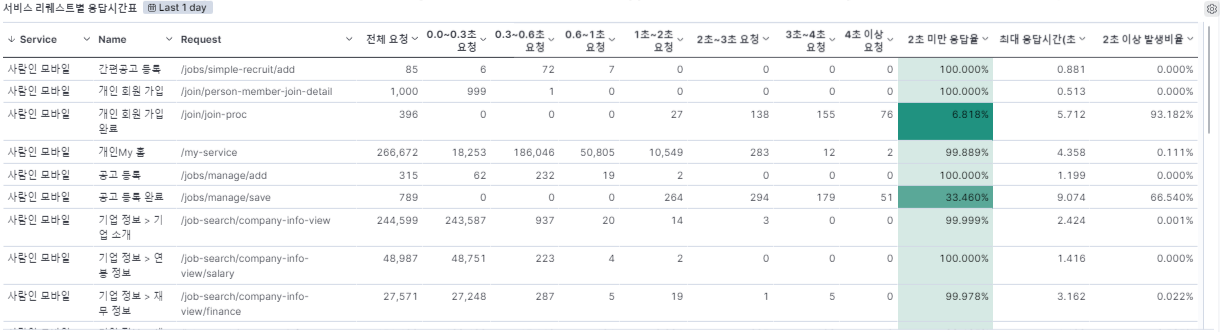
서비스 리퀘스트별 응답시간표 입니다. 해당 Dashboard는 서비스의 Request 별로 전체요청, X초 미만의 요청, 응답율, 최대 응답시간, 2초 이상 발생 비율에 대해서 Aggregation 합니다.
가입 Apply 되는 부분이 2초 이상 발생 비율이 93%나 되네요!
응답율 계산 기준은 upstream_response_time의 값이 0초에서 2초 사이에 status가 200~399 사이의 건 수(Count)의 평균 낸 값 입니다.
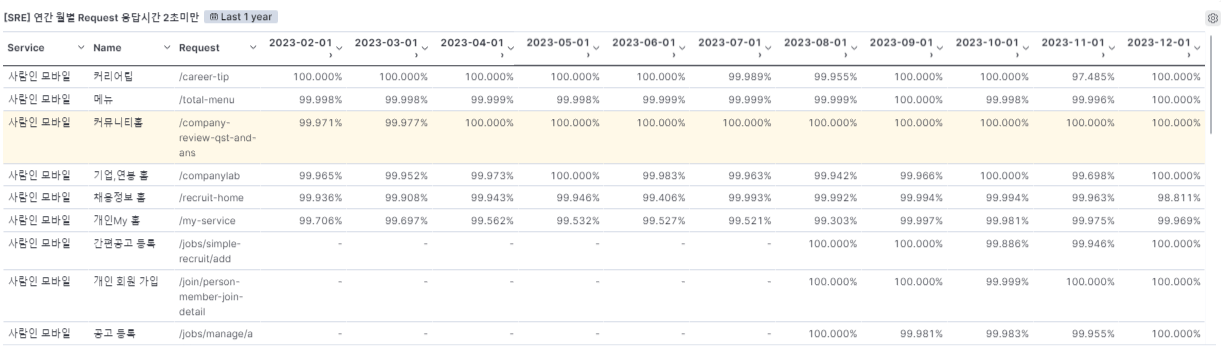
연간 Request 별 응답시간 표 입니다.
1년치 Request에 대해 월마다 어느정도 평균으로 응답했는지 한 눈에 볼 수 있습니다.
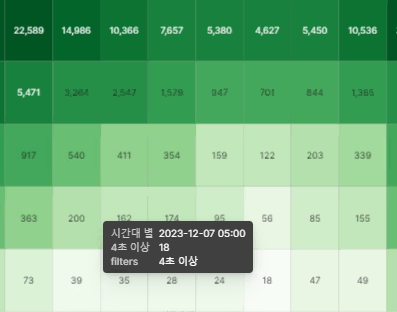
시간대별로 1초미만, 2초미만, 3초미만, 4초미만 등에 대해 어느정도 요청이 몰렸는지 볼 수 있습니다.
전체적으로 요청이 적은 새벽 5시에도 4초 이상 걸린게 18건 이나 발생했네요. 이러면 트래픽에 몰린게 아닌데 불구하고 느리게 동작하는 걸 알 수 있네요.
뭔가 고질적인 게 존재하는건가 싶어요.

SLI로 성공적인 요청에 대해서도 Dashboard를 만들었습니다.
성공적인 요청이라는 건 응답시간 기준이 아닌 응답 코드에 대한 기준이며 전체 응답 코드에서 200~399 코드에 대한 평균을 낸 값입니다.
가끔보면 사람인 모바일인데 웹앱의 My 홈 Request로 들어온 경우도 있네요! 이건 접근 할 수 없는 경로로 접근 했기 때문에 성공 할 수가 없죠.
2건이 4XX에러로 발생 했다는 걸 알 수 있네요.
발생 문제점
이렇게 데이터를 시각화해서 보는건 좋은데..
많은 데이터가 적재 되고 관련 데이터를 연간으로도 봐야 최대 월별로 퍼센테이지가 개선 되는지 확인 할 수 있을텐데, 1년, 2년, 10년치 데이터를 본다 그러면 데이터가 감당 안 됩니다. 데이터양이 어느정도인지 한번 보겠습니다.
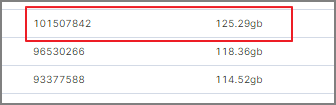
사람인 1개 서비스의 웹앱에 대한 Index 용량만 보더라도 하루에 1억 건으로 약 125GB 씩 쌓입니다.
이게 원본 로그 데이터라고 보면 되는데 이 많은 데이터를 그대로 처리하고 가공하기에는 Document 수도 많고 용량도 많고 하니 불필요한 Field가 있는 Document는 제외하고 Reindexing 진행 하였습니다. 여기서 불필요한 Field라면 사내 IP라든가, 세션 ID가 없거나, 크롤링 여러 가지가 있을거예요.
그렇게 조건을 걸어 새로 Reindex한 데이터 양을 보면
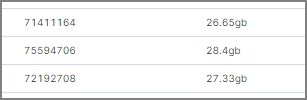
월 28GB 선으로 줄였습니다. 이것도 상당히 많이 줄었습니다. 하루에 125GB였는데 월에 28GB라니~
하지만 월 28GB라고 하더라도 장기보관을 1년, 10년까지 한다고하면 그것 또한 용량이 많아질겁니다. 그리고 Document가 많아지고 용량이 커지면 그거에 따라 Aggregation할 때 Load가 많이 걸리게 됩니다. 당연히 Dashboard 불러 올 때도 Timeout 걸린다거나 힘들어지구요. 장애로 이어질 수도 있는 부분이죠
그래서 Elasticsearch의 Transforms을 이용하게 됐습니다.
Transforms
Transforms을 사용하면 기존 Elasticsearch Index를 Summarized Index로 변환하여 새로운 인사이트와 분석을 할 수 있습니다.
Elasticsearch의 Transforms은 Influx의 Continuous Query 같이 지속적으로 실행 시켜주는 데이터 후처리 방식의 Index 처리 기능입니다. Transform에는 Pivot과 Latest 방식이 있습니다.
Transform의 Pivot을 이용 해 보도록 하겠습니다.
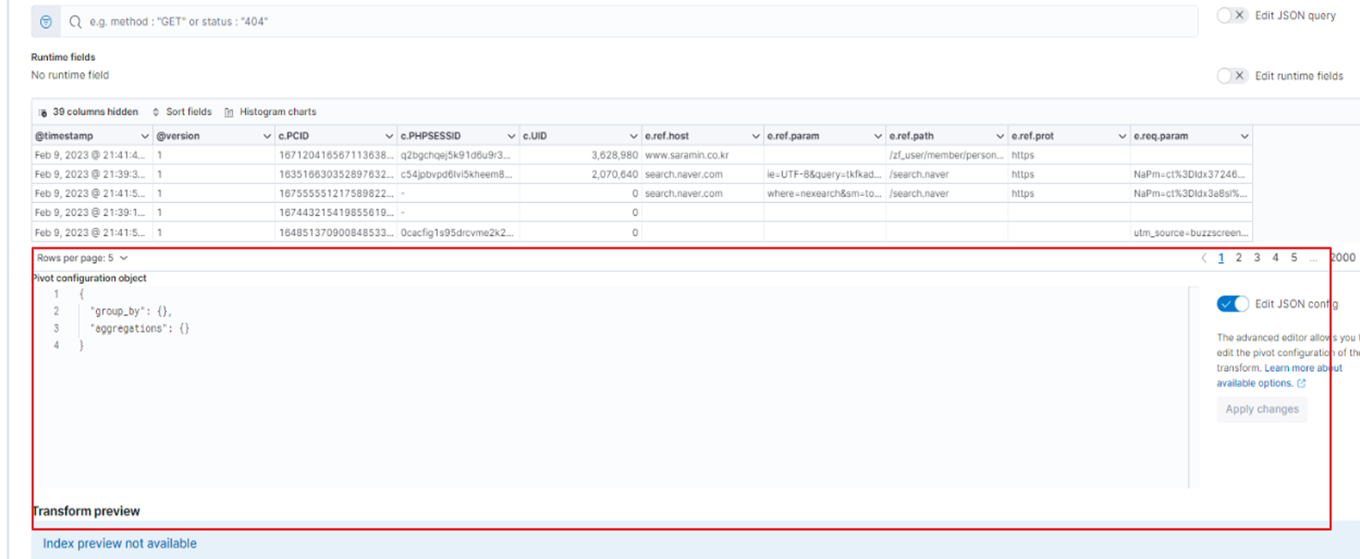
Elastic의 Transform이라는 기능은 GUI로도 설정 할 수 있지만, Dashboard에 산술식이 들어가는 부분이 있다보니 그럴 경우에는 Json 포맷 형식으로 작성해야 합니다.
Code를 보면
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
"group_by": {
"s.domain": {
"terms": {
"field": "s.domain"
}
},
"e.req.path": {
"terms": {
"field": "e.req.path"
}
},
"s.type": {
"terms": {
"field": "s.type"
}
},
"@timestamp": {
"date_histogram": {
"field": "@timestamp",
"calendar_interval": "1m"
}
}
}
먼저 GroupBy로 기준이 되는 항목을 입력 해 줍니다.
저희는 Domain, Request, 그리고 Scripted Fields로 구성한 Type(페이지 이름)을 지정 하였습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
"aggregations": {
"status_filter": {
"filter": {
"range": {
"s.status": {
"gt": 199,
"lte": 399
}
}
},
"aggs": {
"1s_response_range_filter": {
"filter": {
"range": {
"s.upstream_response_time": {
"lt": 1.1
}
}
},
"aggs": {
"1s_range_count": {
"value_count": {
"field": "s.upstream_response_time"
}
}
}
},
"2s_response_range_filter": {
"filter": {
"range": {
"s.upstream_response_time": {
"lt": 2.1
}
}
},
"aggs": {
"2s_range_count": {
"value_count": {
"field": "s.upstream_response_time"
}
}
}
}
Aggregation 부분에 분석에 필요한 정보를 넣어줍니다.
Range에서 le나 ge가 안먹혀서(Bug인가) gt와 lte를 사용하여 기준을 잡았습니다.
Aggregation에 filter는 Range를 지정하여 원하는 값만 필터하기 위해 지정하고,
Aggregation 안에 aggs로 선언을 해서 filter in filter 같은 형태로 구현 할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
"total_response_count": {
"value_count": {
"field": "s.upstream_response_time"
}
},
"response_time_max": {
"max": {
"field": "s.upstream_response_time"
}
},
"avg_response": {
"avg": {
"field": "s.upstream_response_time"
}
},
"status_count": {
"value_count": {
"field": "s.status"
}
},
"gt_4_filter": {
"filter": {
"range": {
"s.upstream_response_time": {
"gt": 3.9
}
}
}
filter in filter 방식이 필요 없다면 aggs 하위에 안두고 선언하면 최상단의 filter를 기반으로 값을 얻을 수 있습니다. 함수는 values_count, max, avg 등이 있어요.
total_response_count를 해석 해보면
예: status code가 200~399인 요청 중에서 total_reponse_count 변수에 upstream_response_time에 대해 value_count 함수를 써서 값을 구한 후 변수에 넣어라.
이렇게 되겠네요.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
"gt_4s_occur_rate": {
"bucket_script": {
"buckets_path": {
"response_count": "status_filter>gt_4_filter>4s_response_count",
"totalResponseTimeCount": "status_filter>total_response_count"
},
"script": "(params.response_count / params.totalResponseTimeCount) * 100",
"format": "00.000"
}
},
"1s_response_rate": {
"bucket_script": {
"buckets_path": {
"responseTimeCount": "status_filter>1s_response_range_filter>1s_range_count",
"totalResponseTimeCount": "status_filter>total_response_count"
},
"script": "(params.responseTimeCount / params.totalResponseTimeCount) * 100",
"format": "00.000"
}
}
Bucket Script를 이용하여 Aggregation에서 입력한 항목에 대해 buckets_path안에 변수를 선언해주고 script 부분에 위에 선언된 변수들과의 산술식이 들어가면 됩니다.
Bucket Script는 부모 Multi Bucket Aggregation 에서 지정된 메트릭에 대해 버킷별 계산을 수행할 수 있는 스크립트를 실행하는 부모 파이프라인 Aggregation입니다. 지정된 메트릭은 값이 Numeric이어야 하며 스크립트는 Numeric 값을 반환해야 합니다.
결과
Tranform을 적용한 후 실제 데이터가 얼마나 줄었을까요? 두둥
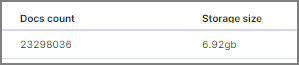
현재까지 약 10개월치 데이터가 6.92GB로 줄었다. 10년을 보관한다고 해도 70GB인 셈이네요.
이렇게 되면 10년은 물론이고 20년, 30년도 가능하겠는데요?
20년 후, 30년 후 하니까 뭔가 징그럽네요. (파뿌리.. 지나간 세월…)
이렇게 Transform을 적용했더니 Canvas에서 Dashboard 로딩 하는 속도도 빨라졌습니다.
각 Dashboard가 Index에 대해 Aggregation 할 필요 없이 이미 Transform에 의해 계산이 완료 된 값을 보여주는 것이기 때문이죠. 이런 측면에서도 성능을 향상 시킬 수 있는 부분인 것 같습니다.
마치며
이렇게 일반적인 시스템의 모니터링 지표만 구해서 보는 것이 아니라, 서비스 관점의 상태 지표인 SLI, SLO를 정하여서 값을 추출 해 내고 시각화 하였고, 장기보관을 위해 어떤 방식을 사용하여 진행 했는지 정리 하였습니다. 단기적으로 보면 드라마틱한 변화가 아닌 이상 큰 변화를 느끼지 못할 텐데, 장기 보관하여 기간을 길게 놓고 보면 어디 부분이 변화 됐는지, 또는 미비 한지 파악이 되며, 개선 목표로 잡아 갈 수 있지 않을까 생각해 봅니다.
감사합니다.