Karpenter 파일럿

지난 포스팅과(사이트 신뢰성에 대한 지표는 어떻게 구성할까?) 다르게 이번엔,
AWS EKS 환경을 좀 더 안정적이며 확장성 있게 운영하기 위해 고민하고 테스트 했던 내용에 대해 공유 드리고자 합니다.
사람인은 K8S 플랫폼으로 On-Premise가 주이고 최근 서비스는 AWS EKS를 사용하고 있습니다.
초기 EKS를 구축 했을 때 CA를 사용하지 않고 Auto Scaling Group을 이용하여 명시적으로 관리 했었습니다.
하지만 거기서 오는 문제점들이 하나씩 발견 되기 시작 했습니다.
문제점.
- 신규 서비스로 낮은 인스턴스 타입 또는 적은 인스턴스의 RI 설정
- 신규 버전에 대해 배포시 많은 리소스 요청으로 인해 Node의
Not Ready상태가 자주 발생 - Auto Scaling Group이 있지만 제대로 감지가 되지 않고, 속도가 느리기 때문에 Node가 죽기 전에
확장 불가 - 문제 발생 할 때 마다
수동으로 노드그룹 수치를 변경하여 축소와 확장으로 임시 조치
문제 발생 할 때 마다 항상 대응 할 수 없고, On-Demand 비용 증가와 안정성 결여로 많은 문제점이 존재 했습니다.
Karpenter란?
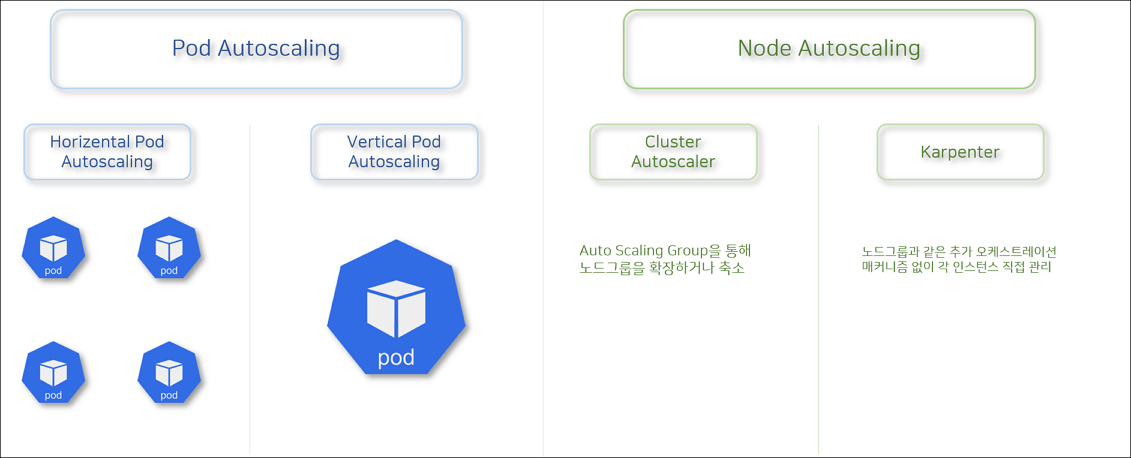
Autoscaling에서도 여러 종류가 있는데,
먼저 Pod Autoscaling으로는 수평적으로 Scale-out 해주는 HPA가 있고 수직으로 Scale-up 해주는 VPA가 있습니다.
Node Autoscaling으로는 CA와 Karpenter가 있는데 Karpenter는 CA와 달리 노드그룹과 같은 추가 오케스트레이션 메커니즘 없이 인스턴스를 직접 관리합니다.
Karpenter 테스트 케이스
Karpenter에 대해 검증을 하기 위해 먼저 케이스를 작성 한다음 케이스에 맞게 테스트를 진행 했습니다.

Karpenter 안정적으로 운영하기
Taint & Toleration
- 노드 어피니티는 노드 셋을 (기본 설정 또는 어려운 요구 사항으로) 끌어들이는 파드의 속성이다. 테인트 는 그 반대로, 노드가 파드 셋을 제외시킬 수 있다.
- 톨러레이션 은 파드에 적용된다. 톨러레이션을 통해 스케줄러는 그와 일치하는 테인트가 있는 파드를 스케줄할 수 있다. 톨러레이션은 스케줄을 허용하지만 보장하지는 않는다. 스케줄러는 그 기능의 일부로서 다른 매개변수를 고려한다.
- 테인트와 톨러레이션은 함께 작동하여 파드가 부적절한 노드에 스케줄되지 않게 한다. 하나 이상의 테인트가 노드에 적용되는데, 이것은 노드가 테인트를 용인하지 않는 파드를 수용해서는 안 된다는 것을 나타낸다.
Karpenter를 안정적으로 운영하기 위해 첫번째로 해야 할 부분이 아무래도 Karpenter Controller를 분리 하는 것일 거 같습니다. Karpenter가 생성한 노드에 자기 자신이 동작하고 있다면 나중에 노드를 줄이게 될 때 Karpenter가 죽게 되는 상황이 발생 할 것 입니다. ASG(Auto Scaling Group)에서 동작하는 노드들에 대해서는 Karpenter Controller, CoreDNS 등 과 같은 Pod가 동작하도록 Taint & Toleration설정을 하였습니다.
ASG 노드에 Taint 설정을 하고, 거기서 동작하는 Pod에 대해 Toleration 설정을 하여 키밸류가 일치 해야만 Running 될 수 있도록 했습니다.
Pod Toleration
1
2
3
4
5
tolerations:
- key: eks
value: asg
effect: NoSchedule
operator: Equal
다중 Node Pool 운영시 Weight 설정
RI 계약이 On-demand 3대로 되어 있기 때문에 ASG 노드 3대에서 1대를 줄이고, Karpenter에서 On-demand를 1대 생성하도록 했습니다. (검증 겸)
Spot Instance Nodepool
1
2
3
4
5
6
7
8
9
10
11
12
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
annotations:
name: spot-instance
spec:
disruption:
budgets:
- nodes: 1%
consolidationPolicy: WhenUnderutilized
expireAfter: Never
weight: 50
On-demand Instance Nodepool
1
2
3
4
5
6
7
8
9
10
11
12
13
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
annotations:
name: ondemand-instance
spec:
disruption:
budgets:
- nodes: 1%
consolidateAfter: Never
consolidationPolicy: WhenEmpty
expireAfter: Never
weight: 1
같은 Node Pool에 karpenter.sh/capacity-type에 spot 과 on-demand를 같이 넣으면 우선순위로 어차피 Spot을 먼저 할당 하겠지만,
노드풀은 나눠놓은 이유는 disruption을 다르게 가져가기 위해서 입니다. on-demand에서는 파드가 완전히 없기 전까지 disruption 하지 않도록 consolidationPolicy를 WhenEmpty로 설정 하였습니다.
그리고 weight를 on-demand를 낮도록 설정하여 spot을 먼저 할당 받도록 했습니다.

매칭 되는 Spot Instance가 없으면 사진과 같이 인스턴스가 없다고 나타납니다.

매칭 되는 Spot Instance가 없으면 on-demand의 Nodepool에서 할당 받게 됩니다.
각 노드에 파드 하나씩 러닝 되도록 분배처리 하기 (TopologySpreadConstraints)
사용자는 토폴로지 분배 제약 조건 을 사용하여 지역(region), 존(zone), 노드 및 기타 사용자 정의 토폴로지 도메인과 같이 장애 도메인으로 설정된 클러스터에 걸쳐 파드가 분배되는 방식을 제어할 수 있다. 이를 통해 고가용성뿐만 아니라 효율적인 리소스 활용의 목적을 이루는 데에도 도움이 된다
파드를 리전, 존, 노드 등의 기준으로 파드를 균등하게 배포 될 수 있도록 하기 위해 설정을 해주었습니다.
1
2
3
4
5
6
7
8
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: "topology.kubernetes.io/zone"
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: ${CI_ENVIRONMENT_SLUG}
maxSkew: 노드간 파드 개수 차이가 최대 1개까지 허용
topologyKey: 이 키를 가진 노드는 동일한 토폴로지에 있는 것으로 간주 합니다.
matchLabels: 일치하는 파드를 찾는데 사용 됩니다.
이러한 설정으로 각 AZ에 파드가 분배 될 수 있도록 합니다.
Pod QoS
Karpenter는 Utilization을 토대로 노드를 할당 해주지 않습니다.
이것은 Kubernetes Schdeduler가 Request 기반으로 동작하기 때문에 이에 맞게 동작하도록 되어 있습니다.
그래서 최대한 Utilization에 맞게 Request를 주는 것이 좋습니다.
다만 Java의 경우 Initializing 때 실제로 사용하는 리소스보다 많이 잡아 먹습니다.
Metric을 보고 Request를 잘 조절 해주면 Karpenter가 빈패킹 단계에서 좀 더 정확하게 인스턴스 타입을 선별 할 수 있도록 합니다.
최대한 게런티 파드로 구성하도록 했습니다.
Kubelet 세팅
Karpenter에서 생성할 노드에서 동작한 Kubelet에 대한 설정도 진행 할 수 있습니다.
이 부분 Karpenter의 영역이라기 보단 EKS에서도 많은 분들이 기본적으로 설정 해두는 부분 입니다.
먼저 kubelet의 Reserved 영역을 지정하는 것 입니다.

Application에서 리소스를 100% 다 잡아 먹는다 하더라도 Reserved 영역을 설정하여 Node Not Ready와 같은 상황에 안빠지도록 안전장치를 추가 했습니다.
1
2
3
4
5
6
7
8
kubeReserved:
cpu: 200m
ephemeral-storage: 3Gi
memory: 100Mi
systemReserved:
cpu: 100m
ephemeral-storage: 1Gi
memory: 100Mi
이렇게 설정하여 인스턴스 리소스를 어플리케이션이 모두 할당해서 Hang 걸리는 일이 없도록 하였습니다.
1
2
imageGCHighThresholdPercent: 80
imageGCLowThresholdPercent: 60
해당 인스턴스의 공간으로 인한 DiskPresure가 발생할 수 있기 때문에 Image Garbage Collection을 위한 WaterMark 설정을 하였습니다.
1
2
3
4
evictionHard:
memory.available: 500Mi
nodefs.available: 10%
nodefs.inodesFree: 5%
eviction에 대한 처리 방식인데, evictionSoft도 있지만 아무래도 eviction 시킬 때에는 노드의 자원 등 위급할 때 배출 하는거라
Hard가 나은 결과로 나왔습니다. 여러 안전장치를 통해 eviction 되는 경우는 거의 줄었습니다.
개발 환경의 경우 업무시간 외에는 Karpenter 노드가 중지되도록(주말, 공휴일, 전사휴무일)
안정성과 확장성을 위해 사용하지만 Spot Instance를 쉽게 이용 할 수 있다는 점에서 비용적인 측면도 무시 할 수 없어서
효율을 극대화 하기 위해 비업무시간에는 Karpenter 노드가 중지되도록 CronJob과 Python code를 걸었습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
apiVersion: batch/v1
kind: CronJob
metadata:
name: karpenter-deprovisioning-cronjob
namespace: karpenter
spec:
timeZone: Asia/Seoul
schedule: "00 22 * * 1-5"
startingDeadlineSeconds: 60
successfulJobsHistoryLimit: 2
failedJobsHistoryLimit: 2
jobTemplate:
spec:
template:
spec:
tolerations:
- key: eks
value: asg
operator: "Equal"
effect: NoSchedule
restartPolicy: Never
serviceAccountName: karpenter
containers:
- name: memory-downsizing-spot
image: bitnami/kubectl
imagePullPolicy: IfNotPresent
command: ["/bin/sh"]
args:
- "-c"
- "kubectl patch nodepools.karpenter.sh spot-instance --type='json' -p='[{\"op\": \"replace\", \"path\":\"/spec/limits/memory\", \"value\":\"0\"}]'"
- name: delete-karpenter-node
image: bitnami/kubectl
imagePullPolicy: IfNotPresent
command: ["/bin/sh"]
args:
- "-c"
- "sleep 10 && kubectl delete nodes -l karpenter.sh/nodepool=spot-instance --force --grace-period=0"
22시 이후에는 Karpenter 노드에 대해 memory limit을 0으로 설정 하도록 했습니다.
Karpenter는 limit의 수치가 설정 되어 있으면 무한정 노드를 만들어 낼 일이 없게 됩니다.
해당 limit 수치를 0으로 설정을 변경하고 노드를 delete 하도록 했습니다.
그러면 ASG노드에 Taint & Tolerations에 의해 모든 Application Pod들은 Pending 상태에서 대기하게 됩니다.
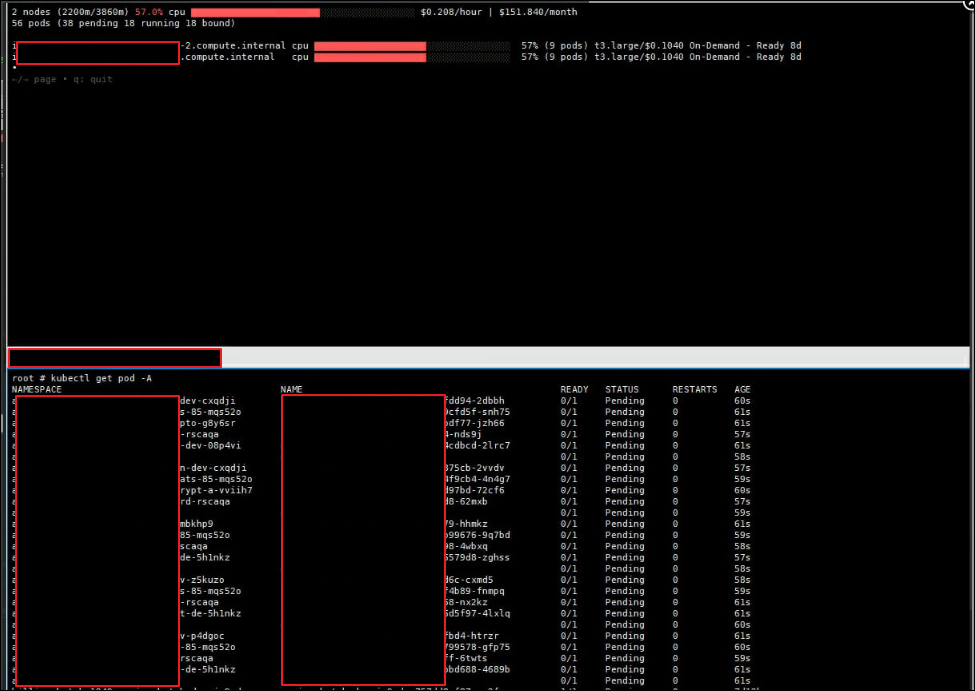 (ASG노드 2대만 동작하고 있고 Karpenter 노드들은 모두 종료 되고 App Pod들은 Pending으로 보인다.)
(ASG노드 2대만 동작하고 있고 Karpenter 노드들은 모두 종료 되고 App Pod들은 Pending으로 보인다.)
그리고 자동으로 업무시간 07시에는 해당 limit 값을 원복 하면 Karpenter는 동작하게 되면서, Application Pod들이 새로 배포하지 않아도 다시 동작하게 되죠
Requirement
Spot Instance를 할당 할 때 instance-cpu와 instance-memory 기준을 잡고 운영 했지만,
과한 인스턴스를 할당 받는다거나, Spot 중에서도 비용이 비싼 인스턴스를 할당 받는 경우가 있었습니다.
또한 07시에 모든 Application Pod가 expanding window algorithm에 의해 최대 10초까지 보류중인 파드들을 단일 배치로 구성 해버리기 때문에
덩치큰 Spot Instance 노드 하나에 모든 Pod를 다 동작시키게 됩니다. 오히려 그게 비용이 저렴 할 수도 있지만
Spot Instance가 Interruption 되버리면 반대로 모든 Pod가 중지 될 수도 있기 때문에 instance-type으로 저희가 원하는 타입으로 리스트업해서 할당 받을 수 있도록 했습니다.
instance-type는 Spot Instance 중에서도 평균적으로 가격이 가장 낮게 책정 되는 Instance Type 위주로 선별 하였습니다.
1
2
3
- key: node.kubernetes.io/instance-type
operator: In
values: ["r6g.xlarge", "m6i.xlarge", "m6g.xlarge" .... ]
instance-type으로 기준을 잡게 되면 15개 이상으로 리스트업 하셔야 합니다.
간단하게 Log로 보는 Karpenter 수행 절차
Karpenter Log를 보면 비슷한 패턴으로 로그가 떨어지는 것을 볼 수 있습니다.
이벤트 found provisionable pod 가 발생 하면
| 노드 생성 단계 순 | 설명 |
|---|---|
computed new nodeclaim |
파드 개수에 맞게 노드를 몇개 만들지 선별 |
create nodeclaim |
노드 요청서(fit에 맞는 노드 타입 리스트업) |
launched |
nodeclaim 중 알맞은 ec2 생성 |
registered |
클러스터에 등록 |
ready |
ready 상태로 되면 |
intialized |
최종 완료 |
노드 삭제 단계
- 노드가 비어있어 노드를 제거 할수있는 경우
- 파드가 줄었거나 더 저렴한 노드로 변경 할 수 있을 경우
| 노드 삭제 단계 | 설명 |
|---|---|
disrupting |
node에 finalizer를 지정하고 노드를 제거 절차가 진행되는동안 제거 방지 |
tained node |
스케쥴되지 않도록 disruption:noschedule이라는 taint를 건다. |
deleted node |
노드 삭제 명령을 수행하고 controller가 정상적으로 종료될때까지 기다림 |
deleted nodeclaim |
최종 완료 되면 nodeclaim 삭제 |
번외
Descheduler
Descheduler과 Karpenter를 같이 사용하면 시너지가 있지 않을까 싶어서 테스트 해보았습니다.
Descheduler에는 크게 기능이 LowNodeUtilization과 HighNodeUtilization이 있습니다.
LowNodeUtilization은 노드간 리소스 사용량을 좀 더 촘촘하게 해서 리소스를 균등하게 사용 할 수 있도록 합니다.
HighNodeUtilization은 리소스 사용량에 따라 노드를 비워주도록 합니다.
Karpenter consolidationPolicy에는 WhenEmpty라는 정책이 있어서 Descheduler가 노드를 비워주면 Karpenter는 WhenEmpty에 의해 동작하여 노드를 제거 해주지 않을까 싶었습니다.
결론적으로 말씀 드리면 Descheduler의 HighNodeUtilization가 Bin-Packing 전략을 사용하기 위해선 Kubernetes Scheduler의 MostAllocated 전략과 함께 사용 되어야 하는데 EKS에서는 기본적으로 ScoringStrategy가 LeastAllocated를 사용합니다.
HighNodeUtilization + LeastAllocated 조합으로는 동작하지 않았습니다.
This strategy must be used with the scheduler scoring strategy MostAllocated.
마무리하면서..
Karpenter는 단순한 메커니즘으로 동작합니다. Pod가 Pending 되면 노드를 늘려준다.
하지만 그 단순한 메커니즘은 시스템에 많은 영향을 끼치기 때문에 안정적으로 운영하기가 매우 까다롭습니다.
그럼에도 불구하고 Karpenter를 사용하는 이유는 강력한 퍼포먼스에 있다고 생각합니다.
노드가 부족할 때 10초만에 생성되고 Ready까지 40초 미만이면 완료 됩니다. 더군다나 Spot 인스턴스 사용을 할 수 있도록 하여 비용적인 측면까지 잡아갈 수 있도록 하였습니다.
Production에 적용하기 전에는 많은 전략 및 테스트를 거쳐서 적용 시키기 바랍니다.
해당 포스팅으로 많은 정보 얻어가셨으면 좋겠습니다. 긴 글 읽어주셔서 감사합니다.