네트워크장비 트래픽 모니터링 - 평균의 함정
SE팀은 사람인HR에서 제공하는 서비스의 전반적인 인프라 구성/운영/관제를 담당하며 서비스가 안정적으로 운영이 되도록 모니터링을 하기 위해 다양한 오픈소스툴을 활용하거나 필요에 따라 직접 개발하기도 합니다. 이번 포스팅은 IDC 의 서비스트래픽 모니터링을 위해 오랜기간 사용중이던 cacti 에서 telegraf, grafana, influxdb 를 활용한 사례를 공유하고자 합니다.
2018년 11월경에 응답속도가 느려지거나 정상적으로 연결되지 않는 현상이 짧게는 수초동안 길게는 몇분간 간헐적으로 발생한 적이 있었습니다.
- 서버 부하등 시스템상으로도 특이사항이 없다
- 5분단위로 수집되는 트래픽도 특이사항이 없다
- IDC 에서 제공해주는 트래픽 차트에도 트래픽과부하는 아니다
- 10초 주기 웹사이트 관제의 경우 메인라인을 통해 접근되는 부분만 응답속도가 느리거나 7초후 timeout 이 발생
짧은 시간동안 발생한 경우는 인지하지 못했거나 1분내외로 발생한 경우 일시적인 문제인가 등 그냥 지나쳐버린 경우도 있었을것입니다. 당시 저는 여기저기 흩어져있던 모니터링화면이 한곳에 집중되어 있길 원했고 그중 스위치트래픽모니터링과 관련된 부분을 먼저 작업중이었는데 차트를 확인하던 중 cacti 와는 조금 다르게 보이는 부분이 있었습니다.
극단적인 예이긴 하지만 만약 5분중에 2분30초간 1Gbps 트래픽이 발생한다고 가정할 경우 아래와 같은 형태일것입니다.
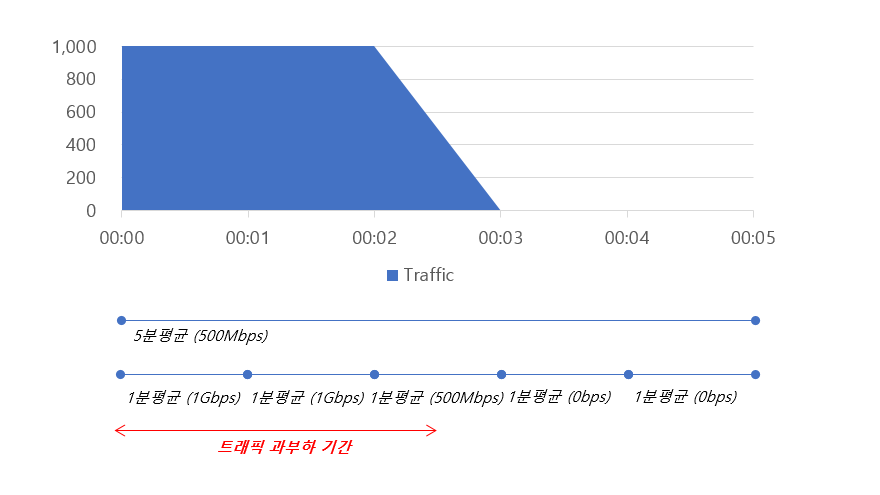
5분간격의 평균과 1분간격의 평균일때 나오는 수치에 큰 차이가 있습니다. 1G 회선의 경우 5분간격의 평균일 경우 트래픽과부하 현상을 인지하지 못하게 되는 문제가 있습니다. 지난 이슈중 일부는 이런 이유로 인해 인지가 늦어진 부분이 있었고 트래픽과부하와 관련됬을거라고 추정은 됬지만 기존 관제의 수치상으로는 트래픽과부하라고 단정하기는 어려운 점이 있었습니다. 이에 수집주기는 짧고 평균을 위한 시간범위도 크지 않게 하면서 트래픽과부하가 발생한 포트에 어떤 장비가 연결되어 있는지에 대한 알림까지 받았으면 좋겠다는 생각이 들었습니다.
바꾸자!!
기존에 수집하던 데몬도 있었지만 가능하면 기존 오픈소스의 가능을 최대한 활용하고 부족한 부분만 채워넣는 형태로 준비했습니다.
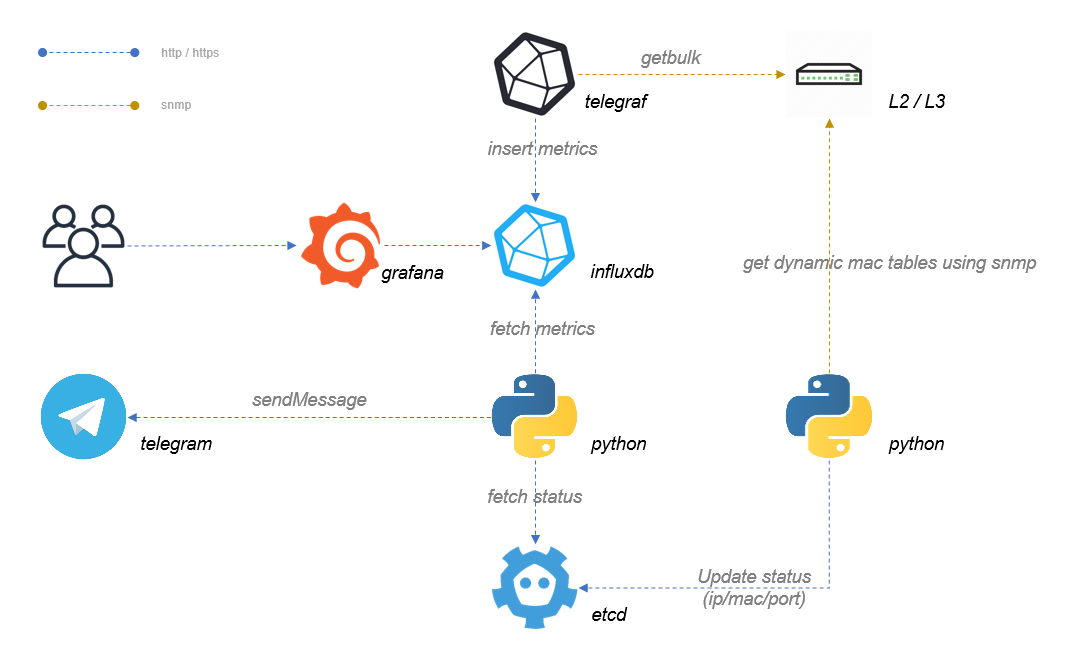
telegraf
다양한 플러그인을 제공하는 모니터링 및 지표 수집 에이전트
influxdb
오픈소스 시계열 데이터베이스로 SQL 계열 언어를 제공
grafana
시계열 메트릭데이터나 로그등의 데이터를 시각화할 수 있도록 대시보드를 제공해주는 Visualization Tool
사전작업
telegraf 가 snmp 프로토콜을 이용하여 metric 데이터를 가져올 수 있도록 네트워크장비에 snmp 설정을 합니다 (예: cisco 장비)
1
snmp-server community __SNMPCOMMUNITY__ RO SARAMIN_ACL
이후에는 linux 서버에서 아래의 명령으로 테스트가 가능합니다
1
snmptable -v2c -c __SNMPCOMMUNITY__ __SNMPHOST__ IF-MIB::ifXTable
구성 설정
telegraf
데이터를 influxdb 에 저장하기 위한 output 설정 /etc/telegraf/telegraf.d/outputs.influxdb.conf
1
2
3
4
5
[[outputs.influxdb]]
urls = ["http://influxdb아이피:8086"]
database = "데이터베이스명"
username = "사용자아이디"
password = "사용자패스워드"
snmp 를 이용하여 수집하기 위한 input 설정 /etc/telegraf/telegraf.d/netdev.conf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
[[inputs.snmp]]
agents = [ "__SNMPHOST__:161" ]
## Timeout for each SNMP query.
timeout = "5s"
## Number of retries to attempt within timeout.
retries = 3
## SNMP version, values can be 1, 2, or 3
version = 2
## SNMP community string.
community = "__SNMPCOMMUNITY__"
## measurement name
name = "network_devices"
[[inputs.snmp.field]]
name = "hostname"
oid = "SNMPv2-MIB::sysName.0"
is_tag = true
[[inputs.snmp.table]]
name = "network_devices"
inherit_tags = [ "hostname" ]
oid = "IF-MIB::ifXTable"
[[inputs.snmp.table.field]]
name = "ifName"
oid = "IF-MIB::ifName"
is_tag = true
influxdb
influxdb 에 정상적으로 기록이 됬는지 확인합니다
1
2
3
> SHOW SERIES FROM network_devices
> SELECT * FROM network_devices WHERE time > NOW()-1m
grafana
grafana 에서는 아래와 같은 쿼리문으로 지정합니다
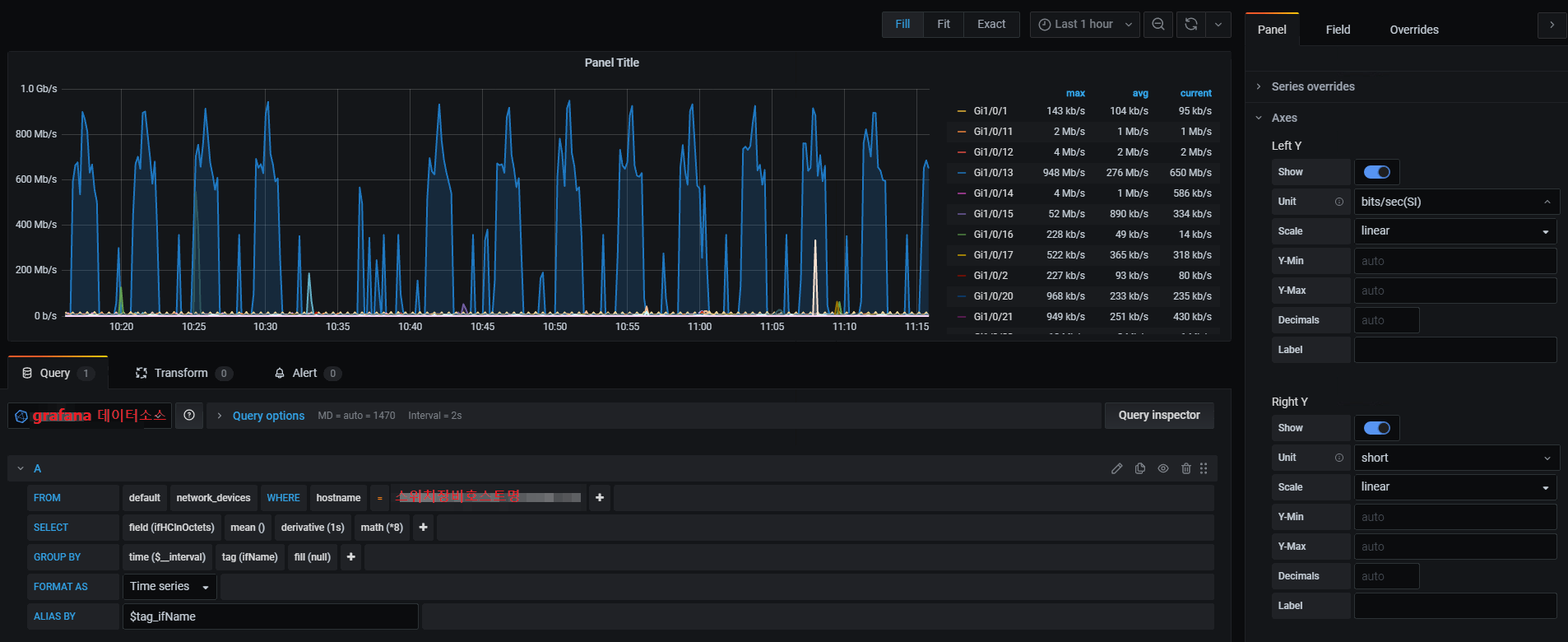
ifHCInOctets 값은 byte 단위이므로 bps 로 계산을 위해 math 함수를 사용하여 8 을 곱했습니다
임계치 이상인 경우 텔레그램으로 알림
grafana 자체적으로 알림기능이 있지만 스위치 포트별로 임계치 이상인 경우 해당 포트에 어떤 장비가 연결되어 있는지 정보까지 알 수 있다면 도움이 될 것 같아 관련부분은 python 을 이용하였습니다.
장비의 포트별 임계치는 아래와 같이 포트명:인바운트임계치,아웃바운드임계치 (Mbps단위) 구조로 되어 있습니다
1
2
3
4
5
6
Gi1/0/1:50,20
Gi1/0/2:300,100
Gi1/0/3:100,100
...
Gi1/0/47:500,500
Gi1/0/48:500,500
python스크립트에서 사용되는 yaml 설정파일
1
2
3
4
5
6
7
8
9
10
11
12
13
14
process:
threads: 50
maxmacs: 10
influxdb:
apiurl: http://INFLUXDB아이피:8086/query
params:
db: INFLUXDB데이터베이스명
u: INFLUXDB사용자아이디
p: INFLUXDB사용자패스워드
epoch: s
query:
- SELECT DERIVATIVE(MEAN("ifHCInOctets"),1s)*8/1024/1024 AS "In" FROM "network_devices" WHERE hostname='{label}' AND time >= NOW() - 5m GROUP BY time(10s),"agent_host","ifName"
- SELECT DERIVATIVE(MEAN("ifHCOutOctets"),1s)*8/1024/1024 AS "Out" FROM "network_devices" WHERE hostname='{label}' AND time >= NOW() - 5m GROUP BY time(10s),"agent_host","ifName"
설정(row변수)을 기반으로 influxdb 로 부터 가져온 metrics 데이터와 비교후 임계치이상인 경우 etcd 의 추가적인 정보와 함께 알림
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
from pydash import py_
import dotmap
import copy
cfg = dotmap.DotMap()
with open('config.yml', 'r') as fd:
buf = yaml.load(fd, Loader=yaml.FullLoader)
cfg = dotmap.DotMap(buf)
kvmap = {
'In': 0,
'Out': 1,
}
# row 는 peewee 를 사용하여 가져온 값
queryfmt = cfg.influxdb.get('query')
if queryfmt and row.comment:
rxtxinfo = py_(row.comment).lines() \
.map_(lambda x: x.strip()) \
.compact() \
.map_(lambda x: re.split("\||:", x, 1)) \
.map_(lambda x: [x[0], x[1].split(",")]) \
.zip_object() \
.value()
_qs = copy.deepcopy(cfg.influxdb.params)
_qs.q = ';'.join(queryfmt).format(**row.__dict__['__data__'])
try:
data = requests.get(cfg.influxdb.apiurl, params=_qs, timeout=10).json()
for _r in data.get('results', []):
for _s in _r.get('series', []):
_type = _s.get('columns')[1]
_port = _s.get('tags').get('ifName')
if _port in rxtxinfo:
maxtraffic = py_(_s['values']).pluck('1') \
.max_() \
.value()
if maxtraffic >= int(rxtxinfo[_port][kvmap[_type]]):
# 알림을 위한 메시지 생성 추가작업루틴
except Exception as e:
logging.info(traceback.format_exc())
참고 자료
참고사항
- Dell OS9, 10 의 경우 snmp 응답값이 약 30초주기로 갱신되는 문제가 있었습니다
- 스위치포트별 dynamic mac table 수집 및 etcd 에 저장등 일부 루틴은 제외되어 있습니다