Kubernetes에서 HPA를 활용한 오토스케일링(Auto Scaling)
소개
채용시스템개발팀은 채용 홈페이지 제작부터 채용 설계, 지원서 접수, 지원자 관리, 데이터 관리, 합격 과정에 이르기까지 원스톱으로 지원하는 채용 솔루션 시스템(등용문 2.5, 5.0, S)을 관리하고 있으며, 그 중 등용문 S는 SaaS형 솔루션으로 Kubernetes(이하 쿠버네티스) 플랫폼을 활용하여 서비스를 제공하고 있습니다.
쿠버네티스는 아래의 구글 트랜드 그래프에서 보시다시피 2014년 중순 구글에서 공개된 이후 지속적으로 증가하였으며 현재에 이르러 사실상 클라우드 업계 표준으로 자리매김하였고 Google Cloud Platform(이하 GCP), Amazon Web Services(이하 AWS), Microsoft Azure(이하 Azure), NAVER Cloud, Kakao i Cloud 등의 많은 퍼블릭 클라우드 컴퓨팅 플랫폼에서도 지원하고 있습니다.
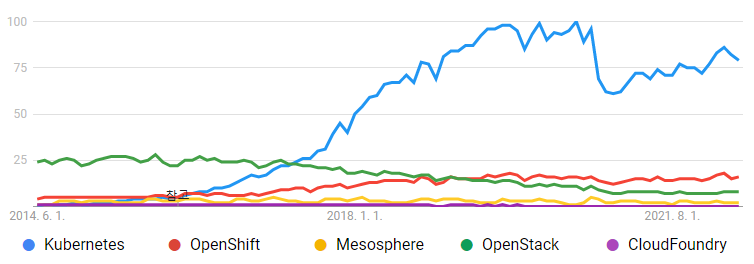
출처 : https://trends.google.co.kr/trends/explore?date=2014-06-01%202022-12-31&q=Kubernetes,OpenShift,Mesosphere,OpenStack,CloudFoundry
이러한 퍼블릭 클라우드 컴퓨팅 플랫폼에서는 리소스를 사용한 만큼 비용이 청구됩니다. 그래서 유입되는 트래픽에 따라 탄력적인 리소스 관리를 위해서 GCP Autoscale groups of VMs, AWS Auto Scaling, Azure Autoscale, NAVER Cloud Auto Scaling, Kakao i Cloud 오토스케일링 등의 기능을 제공하고 있으며 쿠버네티스에서도 Horizontal Pod Autoscaling(이하 HPA)를 제공하고 있습니다.
등용문 S는 쿠버네티스의 HPA를 어떻게 적용하여 사용자들에게 제공하고 있는지를 공유하고자 합니다.
HPA 설치 및 설정
쿠버네티스의 HPA는 HorizontalPodAutoscaler의 scaleTargetRef에 정의된 타겟의 .spec.selector 에 지정된 파드로부터 메트릭을 주기적으로 수집합니다. 만약 각 파드의 컨테이너에 적절한 resources가 설정되어 있다면 수집된 메트릭으로 사용률을 계산하여 오토스케일링 여부를 판단하고 실행하지만, 그렇지 않다면 아무런 조치도 취하지 않습니다.
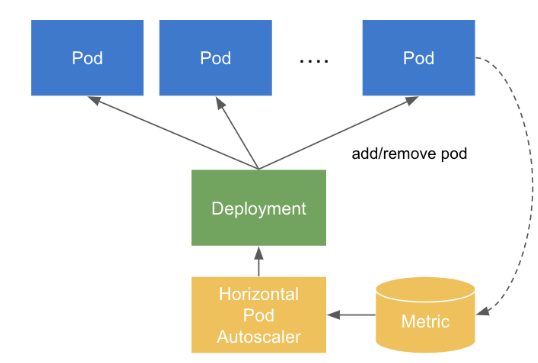
출처 : https://bcho.tistory.com/1349
Chart 설정
등용문 S는 서비스를 배포하기 위해 Helm을 사용하고 있으며, 다음과 같이 deployment.yaml, service.yaml, ingress.yaml, hpa.yaml, values.yaml를 구성하였습니다.
deployment.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ include "app.fullname" . }}
labels:
{{- include "app.labels". | nindent 4 }}
spec:
{{- if not .Values.hpa.enabled }}
replicas: {{ .Values.hpa.minReplicas }}
{{- end }}
selector:
matchLabels:
{{- include "app.selectorLabels" . | nindent 6 }}
template:
metadata:
labels:
{{- include "app.selectorLabels" . | nindent 8 }}
spec:
containers:
- name: nginx
image: nginx:latest
resources:
requests:
cpu: 100m
memory: 90Mi
- name: php-fpm
image: php:fpm
resources:
requests:
cpu: 1000m
limits:
cpu: 1000m
service.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
apiVersion: v1
kind: Service
metadata:
name: {{ include "app.fullname" . }}
labels:
{{- include "app.labels". | nindent 4 }}
spec:
type: ClusterIP
ports:
- port: 80
targetPort: http
protocol: TCP
name: http
selector:
{{- include "app.selectorLabels". | nindent 4 }}
ingress.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: {{ include "app.fullname" . }}
labels:
{{- include "app.labels". | nindent 4 }}
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- http:
paths:
- path: /
backend:
serviceName: {{ include "app.fullname" . }}
servicePort: 80
hpa.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
{{- if .Values.hpa.enabled }}
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: {{ include "app.fullname" . }}
labels:
{{- include "app.labels". | nindent 4 }}
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: {{ include "app.fullname" . }}
minReplicas: {{ .Values.hpa.minReplicas }}
maxReplicas: {{ .Values.hpa.maxReplicas }}
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: {{ .Values.hpa.targetCPUUtilizationPercentage }}
{{- end }}
values.yaml
1
2
3
4
5
hpa:
enabled: true
minReplicas: 3
maxReplicas: 24
targetCPUUtilizationPercentage: 60
이렇게 설정이 끝난 Chart를 설치하고 트래픽이 유입되었는데, HPA가 동작하지 않는걸 확인하였습니다.
Metrics Server 설치
HPA를 사용하기 위해서는 파드로부터 메트릭을 수집하여야 하는데 안되는 것이 원인이었고, Metrics Server라는 애드온을 통해 해결할 수 있기에 Metrics Server installation을 참고하여 다음과 같이 설치합니다.
1
$ kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
그리고 deployment의 .spec.containers.args에 --kubelet-insecure-tls를 추가해줍니다.
1
2
3
4
5
6
7
8
9
10
11
$ kubectl edit deployment metrics-server -n kube-system
...
spec:
...
template:
...
spec:
containers:
- args:
...
- --kubelet-insecure-tls
마지막으로 Metrics Server가 정상적으로 설치되어 동작중인지 확인해줍니다.
1
2
3
4
5
$ kubectl get apiservices
NAME SERVICE AVAILABLE AGE
...
v1beta1.metrics.k8s.io kube-system/metrics-server True 1d
...
이제 메트릭이 정상적으로 수집되면서 HPA 적용은 끝났으며, 이제부터는 모니터링을 통해 minReplicas, maxReplicas, targetAverageUtilization 값을 조정하며 최적화를 진행하시면 됩니다.
트러블 슈팅
갑작스러운 대량의 트래픽이 유입되었지만 HPA 덕분에 탄력적인 서비스가 운영되었습니다. 하지만 오토스케일링 과정에서 간혈적으로 트래픽이 유실되며 502 Bad Gateway 현상을 발견하게 되었습니다. 서비스를 운영함에 있어 단 하나의 트래픽이라도 유실되면 안되기에 험난한 항해를 시작해야 되겠습니다.
Scale Out 과정의 트래픽 유실
먼저 트래픽이 들어오는 구조를 살펴보도록 하겠습니다.
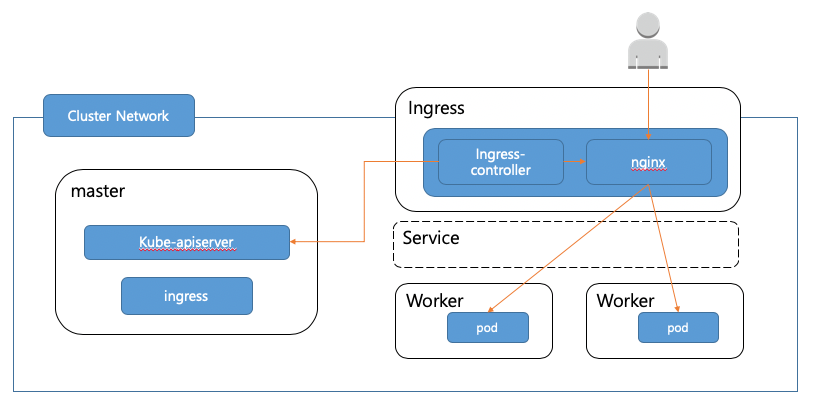
출처 : https://tech.kakao.com/2018/12/24/kubernetes-deploy/
쿠버네티스에서는 하나 이상의 컨테이너로 구성된 파드(Pod) 단위로 배포가 되고 Deployment로 파드와 ReplicaSet을 관리하며 Service와 Ingress를 사용하여 애플리케이션을 외부로 노출하게 됩니다. 이렇게 노출된 어플리케이션으로 트래픽이 유입되고 Ingress를 거쳐 파드에 도착하여 처리된 트래픽은 사용자에게 보여지게 되는데 평소 서비스 운영에서 문제가 없었으므로 트래픽이 파드까지 도달하는데는 문제가 없던 것으로 보입니다. 하지만 대량의 트래픽으로 인해 Scale Out 하며 새로운 파드가 추가될 때 간혈적으로 유실 현상이 나타났으므로 파드에 대해 자세히 알아봐야 할 것 같습니다.
Pod phase
파드의 status는 phase를 포함하는 PodStatus 오브젝트로 정의되며, Pod phase는 다음과 같은 상태를 표시하게 됩니다.
- 파드의 컨테이너가 준비되기까지
Pending - 파드가 노드에 바인딩되었고 모든 컨테이너가 생성되었다면
Running - 파드에 있는 모든 컨테이너가 정상적으로 종료되었다면
Succeeded - Pod의 컨테이너가 하나 이상 실패하여 종료되었을때
Failed - 노드와 통신 오류일 경우
Unknown
이 내용을 바탕으로 생성된 파드를 모니터링 한 결과, Pending을 거쳐 Running으로만 표시되었으며, Failed가 관찰되지 않았으므로 파드에는 문제가 없는 것으로 확인되었습니다. 이제 파드 내부의 컨테이너를 살펴보겠습니다.
Container states
파드가 가지고 있는 각 컨테이너는 다음과 같은 상태를 표시하게 됩니다.
- 컨테이너 이미지를 다운받고 있거나 필요한 시크릿 데이터를 적용중인 경우
Waiting - 컨테이너가 정상적으로 실행되고 있을 경우
Running - 컨테이너가 종료되었거나 실패한 경우
Terminated
이 내용을 바탕으로 생성된 파드의 컨테이너를 모니터링 한 결과, Waiting에서 Running으로만 표시되었으며, Terminated는 관찰되지 않았으므로 컨테이너에도 문제가 없는 것으로 확인되었습니다.
하지만 일부 컨테이너에서 아직 애플리케이션이 준비되지 않았음에도 status가 Running로 표시되며 Pod phase가 Running이 되었고, 그 결과 준비되지 않은 컨테이너가 포함된 파드로 트래픽이 유입되며 유실되는 현상을 확인할 수 있었습니다. 파드의 모든 컨테이너의 준비가 끝난 이후에 트래픽이 유입될 수 있다면 해결될 것 같습니다.
Container probes
Container probes는 컨테이너에서 kubelet에 의해 주기적으로 수행되는 진단(diagnostic)이며, Container spec에 정의되어 있다면 다음과 같은 동작을 수행합니다.
livenessProbe는 파드의 진단 결과Failure일때restartPolicy에 따라서 컨테이너를 종료 또는 재시작 시키도록 동작readinessProbe는 파드는 트래픽을 받지 않는 상태에서 시작하여 진단 결과Success일때 트래픽이 유입되도록 동작startupProbe가 Container spec에 정의되어 있다면 진단 결과Success일때livenessProbe와readinessProbe가 활성화 되도록 동작
Container probes의 startupProbe와 readinessProbe를 활용한다면 컨테이너의 애플리케이션이 준비되었는지 진단하여 트래픽 유입 시기를 조절하고 유실을 막을 수 있을 것으로 파악됩니다. 서비스가 비정상적일때를 대비하여 livenessProbe도 활용하여 다음과 같이 deployment.yaml를 수정하였습니다.
deployment.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ include "app.fullname" . }}
labels:
{{- include "app.labels". | nindent 4 }}
spec:
{{- if not .Values.hpa.enabled }}
replicas: {{ .Values.hpa.minReplicas }}
{{- end }}
selector:
matchLabels:
{{- include "app.selectorLabels" . | nindent 6 }}
template:
metadata:
labels:
{{- include "app.selectorLabels" . | nindent 8 }}
spec:
containers:
- name: nginx
image: nginx:latest
resources:
...
livenessProbe:
tcpSocket:
port: 9000
initialDelaySeconds: 4
periodSeconds: 10
failureThreshold: 3
timeoutSeconds: 3
readinessProbe:
tcpSocket:
port: 9000
initialDelaySeconds: 4
periodSeconds: 10
failureThreshold: 6
timeoutSeconds: 3
startupProbe:
tcpSocket:
port: 9000
initialDelaySeconds: 2
periodSeconds: 3
failureThreshold: 10
timeoutSeconds: 1
- name: php-fpm
image: php:fpm
resources:
...
livenessProbe:
httpGet:
path: /ping
port: 80
initialDelaySeconds: 4
periodSeconds: 10
failureThreshold: 3
timeoutSeconds: 3
readinessProbe:
httpGet:
path: /healthz
port: 80
initialDelaySeconds: 4
periodSeconds: 10
failureThreshold: 6
timeoutSeconds: 5
startupProbe:
httpGet:
path: /healthz
port: 80
initialDelaySeconds: 2
periodSeconds: 3
failureThreshold: 10
timeoutSeconds: 1
다시 트래픽이 유입된 후 모니터링을 시작하였고, 이제 파드가 늘어나도 유실되는 트래픽이 없어졌음을 확인할 수 있습니다.
Scale In 과정의 트래픽 유실
한숨 돌렸다고 생각하였으나 트래픽이 감소하고 파드가 줄어들면서 다시 간혈적으로 트래픽이 유실되기 시작하였습니다. 파드가 종료되는 부분을 살펴보고 원인을 찾아봐야겠습니다.
Termination of Pods
파드의 종료를 요청하면 Pod phase에는 Terminating이 표시된 후 컨테이너에 정의된 container lifecycle hooks의 preStop이 실행되며 동시에 Service와 Ingress에서는 파드를 제거하여 추가 트래픽의 유입을 막아줍니다. preStop이 정의되지 않았거나 실행이 끝났다면, 컨테이너 이미지에 정의된 STOPSIGNAL 또는 SIGTERM 시그널을 컨테이너의 기본 프로세스(PID 1)에 전송하여 안전하게 종료되도록 요청하고, 종료된 파드는 삭제됩니다. 이러한 과정에서 파드와 컨테이너가 terminationGracePeriodSeconds로 정의된 시간 또는 기본 유예 기간인 30초가 지난 후에도 여전히 동작하고 있었다면, SIGKILL 시그널을 컨테이너의 모든 프로세스에 전송하고 파드를 강제 종료시킵니다.
파드가 종료되는 과정들을 살펴본 결과, 유입된 트래픽을 처리하는 도중 STOPSIGNAL 또는 SIGTERM 시그널을 수신받아 프로세스가 종료되어 트래픽이 중단되었거나, Service와 Ingress에서 파드가 제거되는 시점과 컨테이너와 파드가 안전하게 종료되는 시점이 보장되지 않아 트래픽이 유입되었지만 목적지가 이미 종료되었을 상황에서 문제가 발생했을 것이라 추측해보았습니다. 먼저 컨테이너의 STOPSIGNAL에 대해 확인해보겠습니다.
Graceful shutdown
파드가 종료될때는 컨테이너 이미지에 정의된 STOPSIGNAL 또는 SIGTERM 시그널을 컨테이너의 기본 프로세스(PID 1)에 전송하여 안전하게 종료되도록 요청한다고 하였습니다. 본문에 제시된 deployment.yaml에서 정의된 컨테이너는 nginx:latest와 php:fpm 이미지를 사용하고 있으며, nginx:latest의 Dockerfile에서 STOPSIGNAL은 SIGQUIT, 기본 프로세스(PID 1)는 nginx -g daemon off를 쓰고 있는걸 확인할 수 있습니다. php:fpm의 Dockerfile에서도 STOPSIGNAL은 SIGQUIT, 기본 프로세스(PID 1)는 php-fpm을 쓰고 있으며, 실제 빌드된 nginx:latest와 php:fpm의 이미지 레이어 정보에서도 동일하게 확인되었습니다.
SIGQUIT 시그널이 nginx 공식문서에서 graceful shutdown을, man php-fpm에서 graceful stop을 지원하고 있다고 하였으므로 유입된 트래픽을 처리하는 도중 프로세스가 갑작스럽게 종료되는 상황은 발생하지 않는 것으로 파악되었습니다. 그렇다면 안전하게 종료된 컨테이너에 트래픽이 유입되었을 상황만 남았으므로 파드의 종료 요청시 트래픽 유입을 차단함과 동시에 동작하는 container lifecycle hooks의 preStop을 확인해보겠습니다.
container lifecycle hooks
kubelet이 관리하는 컨테이너는 container lifecycle hooks의 postStart 와 preStop 을 통해 컨테이너 라이프사이클의 특정 지점에서 실행할 이벤트를 트리거할 수 있으며, 그 중 preStop은 컨테이너가 Terminated상태에 들어가기 전에 실행됩니다. preStop이 끝난 컨테이너는 이미지에 정의된 STOPSIGNAL 또는 SIGTERM 시그널을 전송받고 프로세스가 안전하게 종료되어 파드가 종료되므로 Service와 Ingress에서 파드가 제거되어 트래픽이 차단된 후 파드의 종료가 시작되도록 시간적으로 여유를 둔다면 해결될 것 같습니다. 그래서 다음과 같이 deployment.yaml에 terminationGracePeriodSeconds와 .lifecycle.preStop를 추가해보았습니다.
deployment.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ include "app.fullname" . }}
labels:
{{- include "app.labels". | nindent 4 }}
spec:
{{- if not .Values.hpa.enabled }}
replicas: {{ .Values.hpa.minReplicas }}
{{- end }}
selector:
matchLabels:
{{- include "app.selectorLabels" . | nindent 6 }}
template:
metadata:
labels:
{{- include "app.selectorLabels" . | nindent 8 }}
spec:
terminationGracePeriodSeconds: 60
containers:
- name: nginx
image: nginx:latest
resources:
...
livenessProbe:
...
readinessProbe:
...
startupProbe:
...
lifecycle:
preStop:
exec:
command: ["/bin/sleep", "30"]
- name: php-fpm
image: php:fpm
resources:
...
livenessProbe:
...
readinessProbe:
...
startupProbe:
...
lifecycle:
preStop:
exec:
command: ["/bin/sleep", "30"]
다시 트래픽이 유입된 후 모니터링을 시작하였고, 이제 파드가 감소하여도 유실되는 트래픽이 없어졌습니다.
무중단 배포(Zero downtime deployment)
서비스 운영에 있어 빠질 수 없는게 업데이트입니다. 쿠버네티스는 다음과 같은 전략(strategy)으로 파드의 업데이트를 지원해주고 있습니다.
- 기존 파드를 종료 후 새로운 파드로 바꿔주는
Recreate - 기존의 파드는 Scale In, 새로운 파드는 Scale Out 하며 점진적으로 파드를 바꿔주는
RollingUpdate
우리는 서비스 중단 없이 파드가 업데이트 되어야 하므로 RollingUpdate를 선택하고 다음과 같이 deployment.yaml에 .spec.strategy을 추가해줍니다.
deployment.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ include "app.fullname" . }}
labels:
{{- include "app.labels". | nindent 4 }}
spec:
{{- if not .Values.hpa.enabled }}
replicas: {{ .Values.hpa.minReplicas }}
{{- end }}
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
selector:
matchLabels:
{{- include "app.selectorLabels" . | nindent 6 }}
template:
metadata:
labels:
{{- include "app.selectorLabels" . | nindent 8 }}
spec:
...
그리고 우리는 앞서 여러 설정을 추가하며 파드의 생성과 종료 과정에서 발생하는 트래픽 유실을 차단하였기에 반복되는 업데이트에서도 안정적으로 서비스를 제공할 수 있게 되었고 무중단 배포는 손쉽게 마무리되었습니다.
마치며
지금까지 쿠버네티스에서 HPA를 적용하고 유입되는 트래픽에 따라 탄력적인 운영이 가능하도록 설정해보았습니다. 그 과정에서 Scale In/Out에서 발생하는 트래픽 유실을 확인하여 조치하였으며, 그 결과 서비스 중단 없이 업데이트도 할 수 있게 되었습니다.
쿠버네티스는 계속 발전해나가고 있기에 나중에 되어서는 이러한 해결 과정이 도움이 되지 않을 수 있지만, 지금 동일한 문제에 직면한 상태에서 이 글을 읽고 계시다면 도움이 되길 바라겠습니다.
마지막으로 많은 도움을 주신 SRE팀과 IT전략팀, 서비스인프라개발팀, 저희 팀원분들께 감사 인사를 드립니다.