Spring Cloud Stream 재시도 구현하기
저희 팀에서는 사람인 내부의 DB Trigger를 제거하고 이를 비동기 분산처리로 변환하는 작업을 진행했습니다. 그 중 Kafka를 통하여 메세지 처리 과정 중에 일부 문제가 있었던 부분을 Spring Cloud Stream을 이용하여 재시도 로직을 구현했습니다. 그 기술적인 구현 과정을 공유드립니다.

문제의 발생
문제는 서버 운영 도중 간헐적으로 MySQL Replication Master DB와 Slave DB간의 싱크가 맞춰지기전에 Slave DB를 조회를 하는 과정에서 문제가 발생하였습니다. 카프카 메세지에서 전달한 해당하는 값을 찾지 못해서 발생했었던 건으로, DB 싱크가 느릴경우 값을 찾지 못해 에러 로그를 발생시켰습니다.
이 문제는 정말 간혹가다가 발생하는 에러였기때문에, Sync 시간만 확보해주면 문제를 빠르게 해결 할 수 있었는데, Spring Cloud Stream에서 이 문제를 해결하는 방법을 찾을수 있었습니다.
Spring Cloud Stream에서의 재시도 구현 방법
재시도에서 쓰이는 용어
이러한 시간을 연장할 수 있는 문제를 해결하기 위해 재시도를 통해 sync 시간을 확보하는 방법을 찾게 되었습니다. 그렇다면 재시도는 어떻게 구현해야할까요? 직접 구현할 수 도 있겠지만, Spring Cloud Stream 내부에는 이미 재시도를 해줄 수 있는 라이브러리가 존재합니다. Spring Retry는 재시도 로직을 쉽게 해주는 라이브러리로 간단한 재시도 template만 존재하면, 특정 함수에 대한 재시도 그리고 그 재시도에 대한 횟수 지정과 같이 세부적인 재시도 설정들을 통해 재시도를 효율적으로 구현할 수 있습니다.
이러한 재시도에서 자주 등장하는 중요 용어 혹은 개념들이 있어 이해도를 높이기 위해 가볍게 짚고 넘어가겠습니다.
1. 백오프 (BackOff)
백오프 정의는 재시도를 동일 조건으로 계속 반복하는 건 의미가 없으므로, 현재 시점에 안될 가능성이 있는 걸 가정합니다. 재시도하는 시간 단위를 배수, 지수 단위로 늘려가면서 재시도를 시행하는 도중 점진적으로 시간을 늘려가는 방식을 택합니다.
백오프 개념에 더 자세히 알고 싶은분들은 AWS에서 설명하는 링크를 첨부합니다. 시간 제한, 재시도 및 지터를 사용한 백오프
2. Exception별로 따로 분리해서 처리 가능
NPE(Null Point Exception)의 경우 재시도를 한다고 해서 문제해결이 되는것이 아닌데, 재시도를 여러번하는 것이 의미가 있을까요?
위와 같은 상황에 맞게끔 특정 예외의 경우 재시도할 필요가 없는데, 어떤 예외는 반드시 해야하는 상황이 있을 수도 있으므로, 그 각각의 경우에 맞는 예외처리를 분리해서 처리할 수 있도록 예외에 따른 재시도 환경을 구성 할 수 있습니다.
3. BackOffExhaust
모든 재시도 로직이 모두 실패로 돌아갔을 경우를 뜻합니다. 재시도를 시도하는 최대 횟수를 지정하고 그 경우에 대해서 최대 횟수만큼 시도이후에도 실패했을때 다음과 같은 에러가 발생하고 종료합니다. 이러한 경우 에러 로그로 모든 재시도 횟수를 시도 했으나 실패했다는 것을 노출시키며, 그 발생했던 문제가 무엇인지에 대해서 노출합니다.
Spring Cloude Stream의 재시도 구현 방식
이러한 용어를 바탕으로 Spring Cloud Stream에서 사용하는 방법에 대해서 설명드리도록 하겠습니다.
1. yaml 파일을 통한 retry 옵션 주기
Spring Retry를 사용하기 위해서는 YAML 옵션으로도 Spring Cloud Stream에서 사용할 수 있도록 구성할 수 있습니다.
Spring Cloud Stream의 경우는 bindings를 통해서 함수 등록이 가능합니다. 그 컨슈머에서 발생한 재시도 횟수를 코드 작성이 아닌, yaml의 옵션을 통해서 적용을 할 수 있습니다. 아래는 재시도와 관련한 옵션에 대한 설명입니다.
1
2
3
4
5
6
7
8
9
10
spring:
cloud:
stream:
bindings:
process-in-0: #함수명
consumer:
max-attempts: #최대시도횟수 = 첫시도(1)+재시도횟수
back-off-initial-interval: #첫 재시도시 몇초 기다릴지 (ms)
back-off-multiplier: #몇 배수로 재시도 시간을 늘릴지 (Double Type)
back-off-max-interval: #최대 시도 시간 (배수로 시간이 증가해도 이 최대값이상으로 늘지 않음)
다음은 간단한 예시를 만들어보았습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
package kr.co.saramin.techblog;
import java.util.function.Consumer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
@SpringBootApplication
public class TechblogApplication {
private static final Logger log = LoggerFactory.getLogger(TechblogApplication.class);
public static void main(String[] args) {
SpringApplication.run(TechblogApplication.class, args);
}
@Bean
public Consumer<String> process(){
return (a) -> {
log.info("{} 는 당연히 되는 것이다.", a);
if(!a.equals("x"))
throw new RuntimeException("에러 발생!!");
};
}
}
그리고 “x”라는 값이 들어오는 케이스만 제외하면 이 함수는 로그를 찍은 뒤, Runtime 에러를 강제로 발생시킵니다. 이러한 에러를 통해서 재시도가 발생하는지 확인해보겠습니다. 재시도와 관련한 옵션은 다음처럼 처리했습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
spring:
cloud:
function:
definition: process;
stream:
bindings:
process-in-0:
destination: test
consumer:
max-attempts: 3
back-off-initial-interval: 1000
back-off-multiplier: 2.0
back-off-max-interval: 5000
설정은 모두 끝났고, 이제 테스트를 해보겠습니다. Kafka의 테스트 토픽에 a와 x라는 문자를 producing 해보았습니다.
 이 함수에 “a” 값이 삽입된 경우는 첫시도 실패 이후에 다음 시도부터는 1초 -> 2초 간격으로 늦게 재시도하며 최종장에 실패한 경우 완전 실패를 뜻하는 exception을 던지게 됩니다.
이 함수에 “a” 값이 삽입된 경우는 첫시도 실패 이후에 다음 시도부터는 1초 -> 2초 간격으로 늦게 재시도하며 최종장에 실패한 경우 완전 실패를 뜻하는 exception을 던지게 됩니다.
 이 함수에 “x” 값이 삽입된 경우는 정상적으로 단 한번만 실행됨을 확인할 수 있습니다. 즉, 재시도가 발생하지 않습니다.
이 함수에 “x” 값이 삽입된 경우는 정상적으로 단 한번만 실행됨을 확인할 수 있습니다. 즉, 재시도가 발생하지 않습니다.
2. @StreamRetryTemplate 를 통해 사용하기
이 방식은 코드로 RetryTemplate를 생성하여 빈등록을 하는 방식으로 재시도에 관련한 여러 옵션들을 구체적으로 설정할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
package kr.co.saramin.techblog;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.cloud.stream.annotation.StreamRetryTemplate;
import org.springframework.context.annotation.Configuration;
import org.springframework.retry.RetryCallback;
import org.springframework.retry.RetryContext;
import org.springframework.retry.RetryListener;
import org.springframework.retry.support.RetryTemplate;
@Configuration
public class RetryTemplateConfig {
private final static Logger log = LoggerFactory.getLogger(RetryTemplateConfig.class);
//에러 발생에 대한 리스너를 구현합니다. (재시도 시작 혹은 에러발생시에 대해서 처리가능)
private final RetryListener listener = new RetryListener() {
....
@Override
public <T, E extends Throwable> void onError(RetryContext retryContext, RetryCallback<T, E> retryCallback, Throwable throwable) {
log.info("=========== RETRY ERROR {} 번째 발생 ================", retryContext.getRetryCount());
log.info("Retry Exception Trace::: ", throwable.getCause());
}
};
@StreamRetryTemplate
public RetryTemplate defaultRetryTemplate(){
return RetryTemplate.builder()
.maxAttempts(4)
.exponentialBackoff(5000, 2.0, 30000)
.withListener(listener)
.build();
}
}
기본적으로 RetryTemplate는 Default로 설정이 되어있는데, 자신이 선택하고자하는 Retry의 형태 템플릿이 따로 존재한다면 그것을 Bean으로 등록하고 @StreamRetryTemplate를 붙혀주기만 하면 기본 재시도 template로 등록이 됩니다.
혹은 새로운 RetryTemplate를 등록하여 함수별 다른 재시도 정책을 가져가게 할 수도 있습니다.
1
2
3
4
5
6
7
8
@StreamRetryTemplate
public RetryTemplate otherRetryTemplate(){
return RetryTemplate.builder()
.maxAttempts(6)
.exponentialBackoff(2000, 5.0, 10000)
.withListener(listener)
.build();
}
1
2
3
4
5
6
7
spring:
cloud:
stream:
bindings:
process-in-0:
consumer:
retry-template-name: otherRetryTemplate #<retry-template-bean 명 등록>
위와 같이 다른 retry의 template를 붙이게된다면…?
 retry-template-name을 설정하지 않는다면, 위의 경우는 기본
retry-template-name을 설정하지 않는다면, 위의 경우는 기본 template로 재시도를 시도하게 됩니다.

retry-template-name 로 함수명을 지정한 경우 -> 6번째의 재시도가 발생함. 즉, 각각의 함수별로 따로 재시도 정책을 지정할 수 있게 됩니다.
실무에서의 주의점
실제로 프로젝트를 진행하면서 다음과 같은 오류도 발생했습니다.
첫번째로 두 개이상 @StreamRetryTemplate가 있는 경우 무조건 처음 등록된걸 기준으로 등록되기때문에(Bean 등록상 우선순위가 높은 순서대로 걸리는 것으로 추정됩니다.) 그 경우 직접 지정해줘야합니다. 기본 DefaultTemplate는 처음 등록된 빈으로 설정됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
@StreamRetryTemplate
public RetryTemplate defaultRetryTemplate(){ //기본 retryTemplate로 설정됩니다.
return RetryTemplate.builder()
.maxAttempts(4)
.exponentialBackoff(5000, 2.0, 30000)
.withListener(listener)
.build();
}
@StreamRetryTemplate
public RetryTemplate otherRetryTemplate(){
return RetryTemplate.builder()
.maxAttempts(6)
.exponentialBackoff(2000, 5.0, 10000)
.withListener(listener)
.build();
}
마지막으로 1번에서 설정한 yaml파일을 통한 설정은 @StreamRetryTemplate를 설정해버리면 빈등록이 무조건 우선순위가 높은 방식으로 빈 등록 배정 받기 때문에 yaml 설정은 무시됩니다. 또한, @StreamRetryTemplate가 하나 등록되있으면 모든 retry-template가 대체되어서 기본 Retry-template는 사라지고 지금 내가 등록한 StreamRetryTemplate 기준으로 모든 함수의 재시도 방식이 설정되므로 주의를 요합니다. 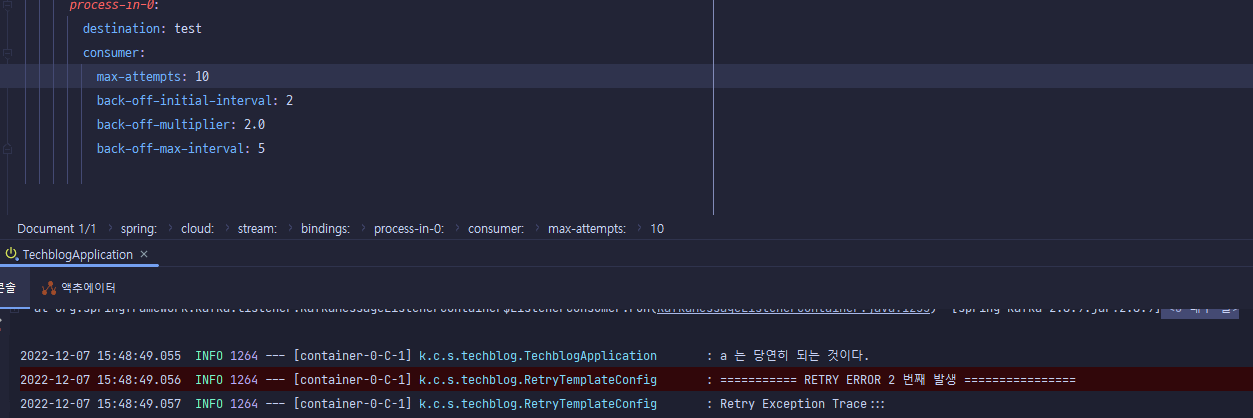 yaml을 적용했지만… 실제로는
yaml을 적용했지만… 실제로는 @StreamRetryTemplate로 적용됩니다.
마무리하며…
Retry Template를 적용하여 문제가 발생했었던 부분들을 효과적으로 해결하였습니다. 이로 인해 동일한 에러는 더이상 발생하지 않았으며, 다른 부분에도 이를 적용하여 눈에 띄게 에러를 줄일 수 있었습니다.
현재 이 프로젝트의 경우 Spring Cloud Stream의 한정하여 Retry 로직을 구현하였으나, Cloud Stream 이외에도 특정 기능에서는 재시도가 반드시 필요할 수도 있습니다. 그런 상황에 대해 Spring Retry를 사용하여 편리하고 로깅에도 최적화되어있는 방식을 사용하는 것을 추천드립니다.