중앙집중식 syslog 설정 및 관제
시스템을 운영하시는 분이라면 대부분 syslog에 대한 감사나 모니터링을 하시고 계실텐데요, 이번 포스팅은 사람인에서 이 syslog를 어떻게 관리하고 모니터링하는지, 그리고 어떤 기준으로 알람을 분류하는지에 대한 내용을 작성하려고 합니다.
전체 구성

syslog
syslog는 포준시스템프로토콜로 kernel을 포함한 시스템데몬등에서 로그를 기록하는데 사용됩니다. 각 로그는 메시지를 발생시킨 프로그램의 타입(facility)과 그 메시지의 중요도(severity) 속성이 존재합니다.
kernel 및 시스템데몬들은 각각 자신만의 기준에서 상태에 따라 severity 별로 로깅을 하는것이 일반적입니다. 따라서 syslog 에 대한 감사및 모니터링은 이슈를 분석하여 해결하는데 도움이 되므로 시스템운영에 있어 반드시 필요한 부분중 하나입니다
아래의 로그메시지는 전통적인 로그메시지형식의 구조를 갖는 예입니다.
1
Dec 21 20:10:17 myhostname systemd[1]: Starting system activity accounting tool...
헤더(날짜와 시간, 호스트또는 아이피)와 메시지(tag, description)로 구분되며 메시지는 tag 는 보통 programname 정보가 기록됩니다.
rsyslog
syslog API 또는 logger cli 를 사용하여 syslog에 로깅이 가능합니다. 리눅스에서는 syslogd(최근 리눅스배포판에는 rsyslogd) 가 해당 매시지를 처리합니다. rsyslog 는 대부분의 리눅스시스템에 기본적으로 설치되어 구동되고 있습니다. 다양한 input,ouput,parser 모듈을 포함하고 있으며 설정 또한 rainerscript 는 프로그래밍과 유사한 형태로 작성이 가능하게 되어 있습니다
filebeat 처럼 다양한 로그수집도구가 존재하는데요, rsyslog 로 사용한 이유가 있습니다
- 원본 로그데이터를 중앙로그서버 로컬디스크에 저장하여 백업
- rsyslog가 이미 설치되어 구동중이므로 설치를 위한 추가작업없이 설정배포만으로 로그포워딩 작업완료
- 포워딩할 syslog 양이 많지 않으므로 단순히 로그포워딩을 위해 rsyslog 로도 충분 (rsyslog가 다른 로그수집도구에 비해 성능이 떨어진다는 의미가 아닙니다)
rsyslog 포워딩 설정
로그포워딩시에는 rfc3339 표준에 맞게 구체적인 날짜시간을 포함하도록 하고 이 시간은 elasticsearch 의 @timestamp 값으로 사용하도록 합니다. 여기서 시간정보는 로그를 전송하는 서버의 시간기준입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
# 전송할 로그메시지의 포맷용 템플릿
# <pri>날짜 호스트명 syslogtag 로그메시지 형태로 정의
template(name="SHRFWDFMT" type="list") {
constant(value="<")
property(name="pri")
constant(value=">")
property(name="timestamp" dateFormat="rfc3339")
constant(value=" ")
property(name="hostname")
constant(value=" ")
property(name="syslogtag" position.from="1" position.to="32")
property(name="msg" spifno1stsp="on" )
property(name="msg")
}
# 룰셋 정의
Ruleset(name="sendToLogServer") {
action(
type = "omfwd"
template = "SHRFWDFMT"
protocol = "tcp"
port = "514"
target = "10.10.1.514"
)
action(
type = "omfwd"
template = "SHRFWDFMT"
protocol = "tcp"
port = "514"
target = "10.10.2.514"
action.execOnlyWhenPreviousIsSuspended = "on"
queue.dequeuebatchsize = "1"
)
}
#
lookup_table(name="exclude_level" file="/etc/rsyslog.d/01-exclude_level.json" reloadOnHUP="on")
set $!exclude_level = lookup("exclude_level", $syslogseverity-text);
# 위에서 정의한 결과가 none 일 경우만 sendToLogServer 룰셋을 호출
if ($!exclude_level == "none") then {
call sendToLogServer
}
- debug 레벨 로그는 포워딩 대상에서 제외하기 위해 lookup_table 과 조건절을 추가하였습니다.
- sendToLogServer 룰셋내 action 에서 execOnlyWhenPreviousIsSuspended 를 사용하여 첫번째 로그서버로 전송실패시 두번째 로그서버로 전송하도록 하였습니다.
로그수신설정
syslog 서버는 아래의 예와 같이 수신된 로그내용에 추가로 ipaddress,facility,severity 를 포함하여 파일에 기록하도록 하고 이 값들은 elasticsearch 에서 검색시 사용될 수 있도록 하였습니다.
1
10.10.10.10 daemon info <30>2023-12-14T16:50:13.301882+09:00 test-server1 systemd[1]: Starting system activity accounting tool...
rsyslog설정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
# 로그포맷을 정의
# 기존 rawmsg 내용앞에 아이피 syslogfacility-text , syslogsrverity-text 를 추가한 내용
template(
name = "loggingFormat"
type = "string"
string = "%FROMHOST-IP% %SYSLOGFACILITY-TEXT% %SYSLOGSEVERITY-TEXT% %rawmsg%\n"
)
# 유입된 로그를 어떤 경로 어떤 파일명으로 저장할지등을 정의하기 위해 만든 템플릿.
# /DATA/SYSLOG/{호스트명}/{년}/{월}/{일}/{logfile}.log 명으로 저장.
template(name="serverLogPath" type="list") {
constant(value="/DATA/SYSLOG")
constant(value="/")
property(name="$.loghost")
constant(value="/")
property(name="timegenerated" dateFormat="year")
constant(value="/")
property(name="timegenerated" dateFormat="month")
constant(value="/")
property(name="timegenerated" dateFormat="day")
constant(value="/")
property(name="$.logfile" )
constant(value=".")
property(name="timegenerated" dateFormat="year")
constant(value="-")
property(name="timegenerated" dateFormat="month")
constant(value="-")
property(name="timegenerated" dateFormat="day")
constant(value=".log")
}
# 로그유입시 이 룰셋이 동작
Ruleset(name="listenLogServer") {
set $.loghost = $hostname;
set $.logfile = "";
if ( prifilt("*.info;mail.none;authpriv.none;cron.none") ) then {
set $.logfile = "messages";
action(type="omfile" dynaFile="serverLogPath" template="loggingFormat")
}
if ( prifilt("authpriv.*") ) then {
set $.logfile = "secure";
action(type="omfile" dynaFile="serverLogPath" template="loggingFormat")
}
if ( prifilt("mail.*") ) then {
set $.logfile = "maillog";
action(type="omfile" dynaFile="serverLogPath" template="loggingFormat")
stop
}
if ( prifilt("cron.*") ) then {
set $.logfile = "cron";
action(type="omfile" dynaFile="serverLogPath" template="loggingFormat")
}
if ( prifilt("uucp,news.crit") ) then {
set $.logfile = "spooler";
action(type="omfile" dynaFile="serverLogPath" template="loggingFormat")
}
if ( prifilt("local7.*") ) then {
set $.logfile = "boot";
action(type="omfile" dynaFile="serverLogPath" template="loggingFormat")
}
# 모든 작업이 완료됐으므로 추가 작업은 하지 않도록 처리루틴을 중단시킨다
stop
}
# rsyslog input 모듈중 udp 모듈을 사용하여 LISTEN 한다.
# 해당 input 으로 유입된 데이터에 대해 listenLogServer 룰셋으로 처리
module(load="imudp")
input(type="imudp" Address="0.0.0.0" port=["514"] Ruleset="listenLogServer")
로그가 유입되면 listenLogServer 룰셋에 맞게 /DATA/SYSLOG/{호스트}/{년}/{월}/{일}/{로그파일}.{년}-{월}-일.log 에 기록하도록 합니다.
Elasticsearch 작업
수집된 로그를 저장한 인덱스의 필드매핑작업을 아래와 같이 하고 logstash 에서도 로그내용을 grok filter 를 사용하여 작업하였습니다.
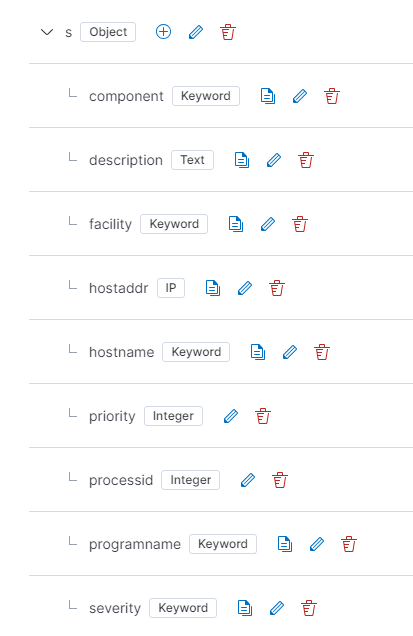
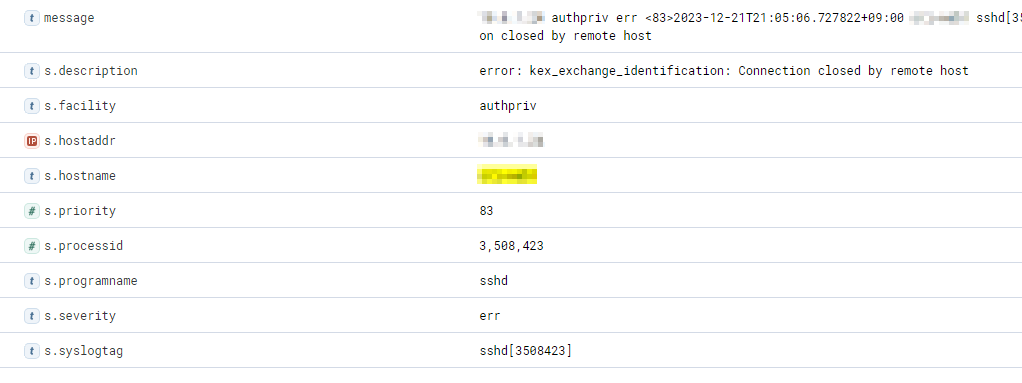
logstash 시에서는 아래의 grok 패턴으로 처리하도록 합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
filter {
grok {
match => {
"message" => [
"^%{IPORHOST:[s][hostaddr]} %{WORD:[s][facility]} %{WORD:[s][severity]} \<%{INT:[s][priority]}\>%{TIMESTAMP_ISO8601:[tmp][hosttime]} %{NOTSPACE:[s][hostname]} %{NOTSPACE:[s][syslogtag]} %{GREEDYDATA:[s][description]}"
]
}
}
if [tmp][hosttime] {
date {
match => [
"[tmp][hosttime]",
"ISO8601"
]
target => "@timestamp"
}
}
}
filebeat
rsyslog 가 저장하는 파일들을 filebeat 를 사용하여 지속적으로 수집하도록 합니다.
1
2
3
4
5
6
7
- type: log
enabled: true
paths:
# /DATA/SYSLOG/{HOSTNAME}/{YYYY}/{mm}/{dd}/{FILENAME}.{YYYY}-{mm}-{dd}.log
- /DATA/SYSLOG/*/*/*/*/*.log
exclude_files:
- '\.gz$'
로그관제를 위한 elastalert
elastalert 는 elastsearch 로 부터 조건에 맞는 데이터가 있을 경우 다양한 어플리케이션으로 알람을 보낼 수 있도록 하는 도구입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
$ python3 -m venv /home/elastalert2
$ cd /home/elastalert2
$ . bin/activate
$ pip install elastalert2
$ deactive
$ mkdir -p etc/rules.d
$ cat << EOF > /home/elastalert2/etc/config.yml
rules_folder: /home/elastalert2/etc/rules.d
run_every:
minutes: 1
buffer_time:
minutes: 15
es_host: Elasticsearch호스트
es_port: 9200
es_username: Elasticsearch사용자
es_password: Elasticsearch패스워드
use_ssl: True
verify_certs: False
ssl_show_warn: False
writeback_index: elastalert_status
alert_time_limit:
days: 2
EOF
$ /home/elastalert2/bin/elastalert-create-index
$ /home/elastalert2/bin/elastalert --config etc/config.yml --verbose
알람 정책
아래의 표는 운영하면서 내부적으로 결정한 정책을 표현한 내용입니다.
kernel 로그는 중요하다고 판단하여 facility 를 kernel 과 나머지로 분류하고 이후 이 두가지를 각 severity 기준으로 분류하였습니다
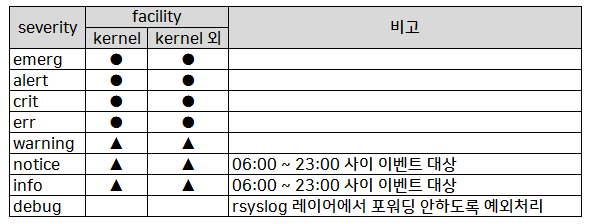
- ● 로그유입시 경보 (일부 예외처리)
- ▲ 지정패턴과 일치하는 로그유입시 경보 (일부 예외처리)
위 표를 기반으로 아래와 같이 룰을 정의할 파일을 분류하고 상황에 따라 패턴 또는 예외처리하도록 하였습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
$ ls -1 switch_severity_*.yml syslog_severity_*.yml
switch_severity_0_emerg.yml
switch_severity_1_alert.yml
switch_severity_2_crit.yml
switch_severity_3_err.yml
switch_severity_4_warning.yml
switch_severity_5_notice.yml
switch_severity_6_info.yml
syslog_severity_0_emerg.yml
syslog_severity_1_alert.yml
syslog_severity_2_crit.yml
syslog_severity_3_err_kernel.yml
syslog_severity_3_err_others.yml
syslog_severity_4_warning_kernel.yml
syslog_severity_4_warning_others.yml
syslog_severity_5_notice_kernel.yml
syslog_severity_5_notice_others.yml
syslog_severity_6_info_kernel.yml
syslog_severity_6_info_others.yml
아래의 예는 각 룰설정파일내 filter 에 해당 하는 항목만 작성한 내용입니다.
syslog_severity_0_emerg.yml
1
2
3
4
5
6
# severity 가 emerg 인 경우 facility 상관없이 모두 알림
filter:
- terms:
s.severity:
- emerg
syslog_severity_4_warning_kernel.yml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# severity 가 warning 이고 facility 가 kern 인 경우
# 지정된 패턴에 포함된 경우 알림
filter:
- terms:
s.facility:
- kern
- terms:
s.severity:
- warning
- warn
# 아래 조건이 1개 이상 매치되는 경우
- bool:
minimum_should_match: 1
should:
- match:
s.description: segfault
- match:
s.description: error
- match:
s.description: fail
- match:
s.description: failed
- match:
s.description: failure
- match_phrase:
s.description: no such file
- match_phrase:
s.description: out of memory
- match_phrase:
s.description: out_of_memory
- match_phrase:
s.description: outofmemory
syslog_severity_4_warning_others.yml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# severity 가 warning 이고 facility 가 kernel 이 아닌 경우
# 지정된 패턴이 포함된 경우 알림
filter:
- terms:
s.severity:
- warning
- warn
- bool:
must_not:
- terms:
s.facility:
- kern
- kernel
# 아래 조건이 1개 이상 매치되는 경우
- bool:
minimum_should_match: 1
should:
- match:
s.description: segfault
- match:
s.description: error
- match:
s.description: fail
- match:
s.description: failed
- match:
s.description: failure
- match_phrase:
s.description: no such file
- match_phrase:
s.description: out of memory
- match_phrase:
s.description: out_of_memory
- match_phrase:
s.description: outofmemory
- match_phrase:
s.description: System clock wrong by
장비별 알람을 발생시키기 위한 aggregation
알람내용에 필드를 포함할 수 있어 수신한 내용으로 대략 어떤 상황인지 파악이 가능합니다. 여러 장비에서 동일한 룰에 의해 발생할 경우 한개의 데이터만 샘플로 수신되기때문에 호스트명기준으로 group by 를 위해 aggregation 을 적용합니다.
1
aggregation_key: s.hostname
위 설정을 적용한 이후 룰의 필터조건에 맞는 로그가 유입시 장비별로 구분하여 각각 알림을 발송하게 됩니다
마치며
수많은 서버의 수많은 로그를 모니터링하는 것은 쉽지 않기때문에 중앙집중식으로 운영및 모니터링하면서 cron syntax 에러처럼 놓쳤던 부분까지 발견할 수 있어 많은 도움이 되었습니다. 사실 syslog서버를 구축하는 것보다 어떤 기준으로 관제대상을 분류및 예외처리부분에 더 많은 시간이 소요됬던것 같은데요, 이런 룰은 운영하면서 필요에 따라 추가및 수정이 필요한 부분들이라고 생각합니다.
그리고 syslog 서버내 디렉토리,파일수가 많아지다보면 filebeat 재구동시 파일을 스캔하는데 시간이 꽤나 소요되어 좀 더 단순화된 구조로 변경하는 것으로 진행하려고 합니다.
참고자료
- https://en.wikipedia.org/wiki/Syslog
- https://www.rsyslog.com/doc/v8-stable/
- https://www.elastic.co/guide/en/beats/filebeat/current/index.html
- https://www.elastic.co/guide/en/logstash/current/index.html
- https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
- https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html
- https://elastalert.readthedocs.io/
- Dell SmartFabric OS10 System Log Message - EQM system log message reference
- Cisco System Log Message Format